


| –§–æ—Ä—É–º –Ý–∞–¥–∏–æ–ö–æ—Ç –ó–¥–µ—Å—å –º–æ–∂–Ω–æ –Ω–µ–º–Ω–æ–∂–∫–æ –ø–æ–º—è—É–∫–∞—Ç—å :) |

|
| –¢–µ–∫—É—â–µ–µ –≤—Ä–µ–º—è: –í—Ç –Ω–æ—è 04, 2025 20:38:23 |
|
–ß–∞—Å–æ–≤–æ–π –ø–æ—è—Å: UTC + 3 —á–∞—Å–∞ |
| –ü–Ý–Ø–ú–û –°–ï–ô–ß–ê–°: |
|
–°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100
–£–∑–µ–ª–∫–∏:
 
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 1 –∏–∑ 1 |
[ –°–æ–æ–±—â–µ–Ω–∏–π: 16 ] |
|
|
| –ê–≤—Ç–æ—Ä | –°–æ–æ–±—â–µ–Ω–∏–µ | |||||
|---|---|---|---|---|---|---|
uk8amk

|
|
|||||
–ö–∞—Ä–º–∞: 16 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 329 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 27, 2007 11:32:06 –°–æ–æ–±—â–µ–Ω–∏–π: 2222 –û—Ç–∫—É–¥–∞: Tashkent –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 7 |
|
|||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
|||||
| –Ý–µ–∫–ª–∞–º–∞ | ||||
|
|
|
|||
|
oleg110592
|
|
||||
–ö–∞—Ä–º–∞: 32 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 482 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°–± —Å–µ–Ω 10, 2011 17:46:25 –°–æ–æ–±—â–µ–Ω–∏–π: 3832 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||

| –Ý–µ–∫–ª–∞–º–∞ | ||||
|
|
|
|||

|
uk8amk
|
|
|||
–ö–∞—Ä–º–∞: 16 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 329 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 27, 2007 11:32:06 –°–æ–æ–±—â–µ–Ω–∏–π: 2222 –û—Ç–∫—É–¥–∞: Tashkent –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
|||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
|||
|
uk8amk
|
|
|||
–ö–∞—Ä–º–∞: 16 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 329 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 27, 2007 11:32:06 –°–æ–æ–±—â–µ–Ω–∏–π: 2222 –û—Ç–∫—É–¥–∞: Tashkent –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
|||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
|||
| –Ý–µ–∫–ª–∞–º–∞ | ||||
|
|
|
|||

|
urry
|
|
||||
–ö–∞—Ä–º–∞: 22 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 81 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü–Ω –¥–µ–∫ 08, 2008 10:58:48 –°–æ–æ–±—â–µ–Ω–∏–π: 1262 –û—Ç–∫—É–¥–∞: –í–∏–Ω–Ω–∏—Ü–∞ –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||

| –Ý–µ–∫–ª–∞–º–∞ | ||||
|
|
|
|||
|
oleg110592
|
|
||||
–ö–∞—Ä–º–∞: 32 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 482 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°–± —Å–µ–Ω 10, 2011 17:46:25 –°–æ–æ–±—â–µ–Ω–∏–π: 3832 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||
| –Ý–µ–∫–ª–∞–º–∞ | ||||
|
|
|
|||


|
uk8amk
|
|
|||
–ö–∞—Ä–º–∞: 16 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 329 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 27, 2007 11:32:06 –°–æ–æ–±—â–µ–Ω–∏–π: 2222 –û—Ç–∫—É–¥–∞: Tashkent –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
|||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
|||
|
balmer
|
|
||||
–ö–∞—Ä–º–∞: 12 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 102 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Å –¥–µ–∫ 02, 2012 03:13:48 –°–æ–æ–±—â–µ–Ω–∏–π: 1433 –û—Ç–∫—É–¥–∞: –ö–∞–ª–∏–Ω–∏–Ω–≥—Ä–∞–¥ –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||

|
oleg110592
|
|
||||
–ö–∞—Ä–º–∞: 32 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 482 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°–± —Å–µ–Ω 10, 2011 17:46:25 –°–æ–æ–±—â–µ–Ω–∏–π: 3832 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||
| –Ý–µ–∫–ª–∞–º–∞ | ||||
|
|
|
|||
|
uk8amk
|
|
|||||
–ö–∞—Ä–º–∞: 16 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 329 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 27, 2007 11:32:06 –°–æ–æ–±—â–µ–Ω–∏–π: 2222 –û—Ç–∫—É–¥–∞: Tashkent –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
|||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
|||||
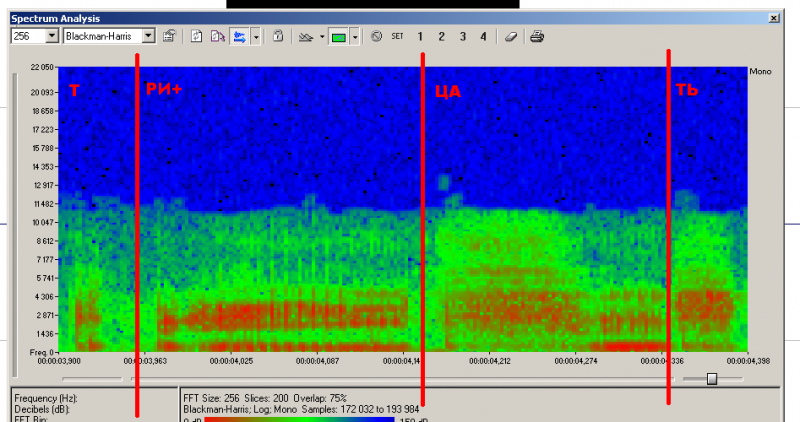
|
uk8amk
|
|
|||
–ö–∞—Ä–º–∞: 16 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 329 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 27, 2007 11:32:06 –°–æ–æ–±—â–µ–Ω–∏–π: 2222 –û—Ç–∫—É–¥–∞: Tashkent –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
|||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
|||
|
fedyasolder
|
|
||||
–ö–∞—Ä–º–∞: 28 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 209 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –º–∞–π 01, 2013 13:53:56 –°–æ–æ–±—â–µ–Ω–∏–π: 2168 –û—Ç–∫—É–¥–∞: —Å –ø–∞–ª—å–º—ã –≤ –Ý–∏–æ-–ò–Ω–∂–µ–Ω–µ–π—Ä–æ –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||

|
oleg110592
|
|
||||
–ö–∞—Ä–º–∞: 32 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 482 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°–± —Å–µ–Ω 10, 2011 17:46:25 –°–æ–æ–±—â–µ–Ω–∏–π: 3832 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||
|
fedyasolder
|
|
||||
–ö–∞—Ä–º–∞: 28 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 209 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –º–∞–π 01, 2013 13:53:56 –°–æ–æ–±—â–µ–Ω–∏–π: 2168 –û—Ç–∫—É–¥–∞: —Å –ø–∞–ª—å–º—ã –≤ –Ý–∏–æ-–ò–Ω–∂–µ–Ω–µ–π—Ä–æ –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||
|
uk8amk
|
|
|||
–ö–∞—Ä–º–∞: 16 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 329 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 27, 2007 11:32:06 –°–æ–æ–±—â–µ–Ω–∏–π: 2222 –û—Ç–∫—É–¥–∞: Tashkent –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 4 |
|
|||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
|||
|
fedyasolder
|
|
||||
–ö–∞—Ä–º–∞: 28 –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 209 –ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –º–∞–π 01, 2013 13:53:56 –°–æ–æ–±—â–µ–Ω–∏–π: 2168 –û—Ç–∫—É–¥–∞: —Å –ø–∞–ª—å–º—ã –≤ –Ý–∏–æ-–ò–Ω–∂–µ–Ω–µ–π—Ä–æ –Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0 |
|
||||
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö | |
||||
|
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 1 –∏–∑ 1 |
[ –°–æ–æ–±—â–µ–Ω–∏–π: 16 ] |
|
–ß–∞—Å–æ–≤–æ–π –ø–æ—è—Å: UTC + 3 —á–∞—Å–∞ |
–ö—Ç–æ —Å–µ–π—á–∞—Å –Ω–∞ —Ñ–æ—Ä—É–º–µ |
–°–µ–π—á–∞—Å —ç—Ç–æ—Ç —Ñ–æ—Ä—É–º –ø—Ä–æ—Å–º–∞—Ç—Ä–∏–≤–∞—é—Ç: –Ω–µ—Ç –∑–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω–Ω—ã—Ö –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π –∏ –≥–æ—Å—Ç–∏: 19 |
| –í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –Ω–∞—á–∏–Ω–∞—Ç—å —Ç–µ–º—ã –í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –æ—Ç–≤–µ—á–∞—Ç—å –Ω–∞ —Å–æ–æ–±—â–µ–Ω–∏—è –í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è –í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —É–¥–∞–ª—è—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è –í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –¥–æ–±–∞–≤–ª—è—Ç—å –≤–ª–æ–∂–µ–Ω–∏—è |