|
–§–æ—Ä—É–º –Ý–∞–¥–∏–æ–ö–æ—Ç • –ü—Ä–æ—Å–º–æ—Ç—Ä —Ç–µ–º—ã - AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4
–°–æ–æ–±—â–µ–Ω–∏—è –±–µ–∑ –æ—Ç–≤–µ—Ç–æ–≤ | –ê–∫—Ç–∏–≤–Ω—ã–µ —Ç–µ–º—ã
 
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 1 –∏–∑ 1
|
[ –°–æ–æ–±—â–µ–Ω–∏–π: 14 ] |
|
| –ê–≤—Ç–æ—Ä |
–°–æ–æ–±—â–µ–Ω–∏–µ |
DmitryKhom

|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4  –î–æ–±–∞–≤–ª–µ–Ω–æ: –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Ç –∞–≤–≥ 08, 2023 21:13:56 |
|
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 08, 2023 20:38:46
–°–æ–æ–±—â–µ–Ω–∏–π: 4
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
–í—Å–µ–º –¥–æ–±—Ä–æ–≥–æ –≤—Ä–µ–º–µ–Ω–∏!
–ó–∞–Ω—è–ª—Å—è –ø–µ—Ä–µ–Ω–æ—Å–æ–º –ø—Ä–æ–≥—Ä–∞–º–º —Å STM32F745 –Ω–∞ AT32F437 –∏ –Ω–∞—Ç–∫–Ω—É–ª—Å—è –Ω–∞ –≤–µ—â–∏, –Ω–µ —Å–æ–≤–º–µ—Å—Ç–∏–º—ã–µ —Å –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏–µ–π.... –¢–∞–∫–∂–µ –¥–ª—è –º–µ–Ω—è –±—ã–ª–æ –Ω–æ–≤–æ—Å—Ç—å—é, —á—Ç–æ –µ—Å–ª–∏ –∏—Å–ø–æ–ª—å–∑—É–µ—à—å –∫–≤–∞—Ä—Ü 25 –ú–ì—Ü, —Ç–æ –≤—ã—Å—Ç—Ä–æ–∏—Ç—å 288 –ú–ì—Ü –Ω–µ –ø–æ–ª—É—á–∏—Ç—Å—è. –ê –µ—Å–ª–∏ –≤–∑—è—Ç—å –∏–Ω–æ–π –∫–≤–∞—Ä—Ü, —Ç–æ –Ω–µ –ø–æ–ª—É—á–∏—Ç—Å—è —Å CLKOUT –≤—ã–¥–∞—Ç—å 25/50 –ú–ì—Ü –¥–ª—è —Ä–∞–±–æ—Ç—ã ETH PHY. –ü–µ—á–∞–ª—å–∫–∞, –Ω–æ –ø—Ä–∏–¥–µ—Ç—Å—è –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –∫–≤–∞—Ä—Ü 16 –ú–ì—Ü, —Ä–∞–∑–≥–æ–Ω—è—Ç—å –¥–æ 288 –ú–ì—Ü, –∞ –¥–ª—è ETH –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å —Å–≤–æ–π —Å–æ–±—Å—Ç–≤–µ–Ω–Ω—ã–π –∫–≤–∞—Ä—Ü –∏–ª–∏ –≥–µ–Ω–µ—Ä–∞—Ç–æ—Ä.
–ù–æ –¥–µ–ª–æ –¥–∞–∂–µ –Ω–µ –≤ —ç—Ç–æ–º.
–Ø –≤–∏–∂—É, —á—Ç–æ –Ω–µ–∫–æ—Ç–æ—Ä—ã–µ –∞—Å—Å–µ–º–±–ª–µ—Ä–Ω—ã–µ –∫–æ–º–∞–Ω–¥—ã –∏—Å–ø–æ–ª–Ω—è—é—Ç—Å—è –≥–¥–µ-—Ç–æ –∑–∞ 6-7 –Ω—Å, –Ω–æ –Ω–µ–∫–æ—Ç–æ—Ä—ã–µ - –∞–∂ –∑–∞ 28-36 –Ω—Å!
–ß—Ç–æ —è —Å–¥–µ–ª–∞–ª.
–Ø —Ä–∞–∑–æ–≥–Ω–∞–ª AT –¥–æ 288 –ú–ì—Ü. –ü—Ä–æ–≤–µ—Ä–∏–ª –Ω–∞ —Ç–∞–π–º–µ—Ä–µ - –¥–µ–π—Å—Ç–≤–∏—Ç–µ–ª—å–Ω–æ, —ç—Ç–æ —Ç–∞–∫: —Ç–∞–π–º–µ—Ä TMR2 –ø—Ä–æ—Ö–æ–¥–∏—Ç —Ä–æ–≤–Ω–æ –∑–∞ 1 —Å–µ–∫—É–Ω–¥—É 144000 —Ç–∞–∫—Ç–∞.
–Ø –≤ –° –æ–ø–∏—Å–∞–ª PF10 –∫–∞–∫ –≤—ã—Ö–æ–¥, –∞ –≤ asm –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–ª –∫–æ–º–∞–Ω–¥—ã –¥–ª—è –±—ã—Å—Ç—Ä–æ–π SET/CLR:
; –∫–æ–¥ —É—Å—Ç–∞–Ω–æ–≤–∫–∏ –±–∏—Ç–∞
LDR R5, GPIO_DBG_ptr ;; GPIO_DBG_ptr —Å–æ–¥–µ—Ä–∂–∏—Ç GPIOF_BASE + —Å–º–µ—â–µ–Ω–∏–µ —Ä–µ–≥–∏—Å—Ç—Ä–∞ SCR
LDR R5, [R5] ; –ì—Ä—É–∑–∏–º –∞–¥—Ä–µ—Å GPIOF->SCR
MOVS R4, #DBG_SET_BSRR ; R4 <= 1<<10
STR R4, [R5] ; –°–æ—Ö—Ä–∞–Ω—è–µ–º 4 –∫–æ–º–∞–Ω–¥–∞
; –∫–æ–¥ —Å–±—Ä–æ—Å–∞ –±–∏—Ç–∞
LDR R5, GPIO_DBG_ptr ; 5 –∫–æ–º–∞–Ω–¥–∞
LDR R5, [R5] ; –ì—Ä—É–∑–∏–º –∞–¥—Ä–µ—Å GPIOF->SCR
MOVS R4, #DBG_CLR_BSRR ; R4 <= 1<<(10+16)
STR R4, [R5] ; –°–æ—Ö—Ä–∞–Ω—è–µ–º 8 –∫–æ–º–∞–Ω–¥–∞
–ö–æ–¥ —Ä–∞–∑–º–µ—Å—Ç–∏–ª –≤ FLASH, –≤—Å—è –ø—Ä–æ–≥—Ä–∞–º–º–∞ —Ü–µ–ª–∏–∫–æ–º (–≤–∫–ª—é—á–∞—è —ç—Ç–∏ –∫–æ–º–∞–Ω–¥—ã) –≤–ª–µ–∑–ª–∞ —á—É—Ç—å –±–æ–ª–µ–µ —á–µ–º 16 –∫–ë, –∑–∞–≥—Ä—É–∂–µ–Ω–∞ –Ω–∞—á–∏–Ω–∞—è —Å 0x08000000, —Ç.–µ. –æ–Ω–∞ 100% –ø–æ–ø–∞–ª–∞ –≤ –æ–±–ª–∞—Å—Ç—å NWS (WS=0).
–ï—Å–ª–∏ –ø—Ä–æ—Å—Ç–æ –∑–∞–ø—É—Å—Ç–∏—Ç—å —ç—Ç–∏ 8 –∫–æ–º–∞–Ω–¥, —Ç–æ –ø—Ä–∏ –ø–æ–º–æ—â–∏ –æ—Å—Ü–∏–ª–ª–æ–≥—Ä–∞—Ñ–∞ –º–æ–∂–Ω–æ –ø–æ–π–º–∞—Ç—å –∏–º–ø—É–ª—å—Å –¥–ª–∏–Ω–æ–π –∞–∂ –≤ 70 –Ω—Å!
–ò–¥–µ–º –¥–∞–ª—å—à–µ. –ï—Å–ª–∏ —É–±—Ä–∞—Ç—å –∫–æ–º–∞–Ω–¥—ã 5-6, —Ç–æ –∏–º–ø—É–ª—å—Å —Ä–µ–∑–∫–æ —Å–æ–∫—Ä–∞—â–∞–µ—Ç—Å—è –¥–æ 10 –Ω—Å.
–û–ø—ã—Ç–Ω—ã–º –ø—É—Ç–µ–º –≤—ã—è—Å–Ω–∏–ª, —Å–∫–æ–ª—å–∫–æ –∏—Å–ø–æ–ª–Ω—è—é—Ç—Å—è –∫–∞–∂–¥–∞—è –∏–∑ –∫–æ–º–∞–Ω–¥:
LDR R5, GPIO_DBG_ptr ; 36 –Ω—Å! (—ç—Ç–æ –ø–æ —Å—É—Ç–∏ –∫–æ–º–∞–Ω–¥–∞ LDR R5, [PC + 60], PC —Å–º–æ—Ç—Ä–∏—Ç –Ω–∞ Flash NWS (0 WS))
LDR R5, [R5] ; 24 –Ω—Å!
MOVS R4, #DBG_SET_BSRR ; —ç—Ç–∞ –∏ —Å–ª–µ–¥—É—é—â–∞—è - –æ–∫–æ–ª–æ 10 –Ω—Å.
STR R4, [R5] ;
–ü–æ–ª—É—á–∞–µ—Ç—Å—è, —á—Ç–æ –≤–∑—è—Ç—å –∑–Ω–∞—á–µ–Ω–∏–µ –∏–∑ –ø–µ—Ä–∏—Ñ–µ—Ä–∏–∏ –¥–æ–ª—å—à–µ, —á–µ–º —Ç—É–¥–∞ –ø–æ–ª–æ–∂–∏—Ç—å....
–ú–æ–∂–µ—Ç –∫—Ç–æ-–Ω–∏–±—É–¥—å –≤ –∫—É—Ä—Å–µ, —á—Ç–æ –º–æ–∂–Ω–æ —Å–¥–µ–ª–∞—Ç—å, —á—Ç–æ–±—ã –Ω–∏–≤–µ–ª–∏—Ä–æ–≤–∞—Ç—å —Ç–∞–∫—É—é —Ä–∞–∑–Ω–∏—Ü—É?
–í—Å–µ–º —Å–ø–∞—Å–∏–±–æ
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
 |
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
VladislavS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –°—Ä –∞–≤–≥ 09, 2023 07:00:31 |
|
| –°–æ–±—É—Ç—ã–ª—å–Ω–∏–∫ –ö–æ—Ç–∞ |
 |
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 433
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –º–∞–π 01, 2018 19:44:47
–°–æ–æ–±—â–µ–Ω–∏–π: 2557
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
–ü–µ—Ä–∏—Ñ–µ—Ä–∏—è —Ä–∞–±–æ—Ç–∞–µ—Ç –Ω–µ –Ω–∞ —á–∞—Å—Ç–æ—Ç–µ –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–∞, –∞ –Ω–∞ —á–∞—Å—Ç–æ—Ç–µ —à–∏–Ω—ã –Ω–∞ –∫–æ—Ç–æ—Ä–æ–π –ø–æ–¥–∫–ª—é—á–µ–Ω–∞. –ê —á–∞—Å—Ç–æ—Ç—ã —à–∏–Ω –æ–±—ã—á–Ω–æ –∫—Ä–∞—Ç–Ω–æ –Ω–∏–∂–µ.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
jcxz
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –°—Ä –∞–≤–≥ 09, 2023 21:12:30 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
–ö–∞—Ä–º–∞: -7
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 188
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 15, 2017 10:51:13
–°–æ–æ–±—â–µ–Ω–∏–π: 1667
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ú–æ–∂–µ—Ç –∫—Ç–æ-–Ω–∏–±—É–¥—å –≤ –∫—É—Ä—Å–µ, —á—Ç–æ –º–æ–∂–Ω–æ —Å–¥–µ–ª–∞—Ç—å, —á—Ç–æ–±—ã –Ω–∏–≤–µ–ª–∏—Ä–æ–≤–∞—Ç—å —Ç–∞–∫—É—é —Ä–∞–∑–Ω–∏—Ü—É? –î–ª—è –∏–∑–º–µ—Ä–µ–Ω–∏—è –≤—Ä–µ–º—ë–Ω –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–º–∞–Ω–¥ —Å–ª–µ–¥—É–µ—Ç –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å —Ç–∞–π–º–µ—Ä DWT:  –ó–∞–ø—Ä–µ—Ç–∏–≤ –ø—Ä–µ—Ä—ã–≤–∞–Ω–∏—è. –ê –≤—ã –∏–∑–º–µ—Ä—è–µ—Ç–µ —Å–∫–æ—Ä–æ—Å—Ç—å GPIO, –∞ –Ω–µ –∫–æ–º–∞–Ω–¥.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
GARMIN
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç –∞–≤–≥ 11, 2023 08:19:41 |
|
| –î–µ—Ä–∂–∏—Ç –ø–∞—è–ª—å–Ω–∏–∫ —Ö–≤–æ—Å—Ç–æ–º |
 |
–ö–∞—Ä–º–∞: 16
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 210
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Å –¥–µ–∫ 02, 2012 16:58:33
–°–æ–æ–±—â–µ–Ω–∏–π: 937
–û—Ç–∫—É–¥–∞: –æ—Ç —Ç—É–¥–∞
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
–ê –µ—â—ë –µ—Å—Ç—å FLASH latency, —Ç–∞–∫ –∫–∞–∫ –∫–æ–º–∞–Ω–¥–∞–º –Ω—É–∂–Ω–æ –≤—Ä–µ–º—è –Ω–∞ –∑–∞–≥—Ä—É–∑–∫—É –∏–∑ —Ñ–ª–µ—à–∞. –ü–ª—é—Å –∫–æ–Ω–≤–µ–π–µ—Ä –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–º–∞–Ω–¥ –º–æ–∂–µ—Ç –±—ã—Ç—å –∑–∞–≥—Ä—É–∂–µ–Ω –∏–ª–∏ –Ω–µ—Ç –≤ –∑–∞–≤–∏—Å–∏–º–æ—Å—Ç–∏ –æ—Ç –ø—Ä–µ–¥—ã–¥—É—â–∏—Ö –∫–æ–º–∞–Ω–¥.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
DmitryKhom
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –∞–≤–≥ 12, 2023 22:15:14 |
|
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 08, 2023 20:38:46
–°–æ–æ–±—â–µ–Ω–∏–π: 4
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–¢–∞–∫ –ø–æ–ª—É—á–∏–ª–æ—Å—å, —á—Ç–æ –æ—Å–Ω–æ–≤–Ω–æ–µ –æ–±—Å—É–∂–¥–µ–Ω–∏–µ –∏–¥—ë—Ç –Ω–∞ –¥—Ä—É–≥–æ–º —Ñ–æ—Ä—É–º–µ (–º–æ–∂–Ω–æ –ª–µ–≥–∫–æ –ø–æ–≥—É–≥–ª–∏—Ç—å –ø–æ –Ω–∞–∑–≤–∞–Ω–∏—é —Ç–µ–º—ã). –ü–æ –∏—Ç–æ–≥–∞–º –æ–±—Å—É–∂–¥–µ–Ω–∏—è —Å–æ–æ–±—â—É —Ä–µ–∑—É–ª—å—Ç–∞—Ç. –í–∫—Ä–∞—Ç—Ü–µ: –∫–æ–Ω–≤–µ–π–µ—Ä –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–∞ –ø–∞—Ä–∞–ª–µ–ª–ª–∏–∑—É–µ—Ç –∑–∞–ø—Ä–æ—Å—ã. –ï—Å–ª–∏ —Å–Ω–∞—á–∞–ª–∞ –∑–∞–≥—Ä—É–∑–∏—Ç—å –≤ —Ä–µ–≥–∏—Å—Ç—Ä, –ø–æ—Ç–æ–º –æ–±—Ä–∞–±–∞—Ç—ã–≤–∞—Ç—å, –ø–æ—Ç–æ–º –µ–≥–æ —Å–æ—Ö—Ä–∞–Ω—è—Ç—å - –ø–æ–ª—É—á–∏—Ç—Å—è –¥–æ–ª–≥–∞—è —Ä–∞–±–æ—Ç–∞, —Ç.–∫. —Å–∞–º–∞ –ø–æ —Å–µ–±–µ –æ–ø–µ—Ä–∞—Ü–∏—è —á—Ç–µ–Ω–∏—è –¥–æ–ª–≥–∞—è, –∏ –æ–Ω–∞ –∑–∞—Ç—è–Ω–µ—Ç—Å—è, –µ—Å–ª–∏ —Å—Ä–∞–∑—É –ø–æ–ø—ã—Ç–∞—Ç—å—Å—è —ç—Ç–∏–º —Ä–µ–≥–∏—Å—Ç—Ä–æ–º –≤–æ—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å—Å—è. –ù–æ —ç—Ç–æ –≥–∏–ø–æ—Ç–µ–∑–∞, –∞ –ø—Ä–∞–≤–¥–∞ –∏–ª–∏ –Ω–µ—Ç - –ø—Ä–æ–≤–µ—Ä—é –≤ –ø–æ–Ω–µ–¥–µ–ª—å–Ω–∏–∫. –î–æ–±–∞–≤–ª–µ–Ω–æ after 4 minutes 55 seconds:–ê –µ—â—ë –µ—Å—Ç—å FLASH latency, —Ç–∞–∫ –∫–∞–∫ –∫–æ–º–∞–Ω–¥–∞–º –Ω—É–∂–Ω–æ –≤—Ä–µ–º—è –Ω–∞ –∑–∞–≥—Ä—É–∑–∫—É –∏–∑ —Ñ–ª–µ—à–∞. –ü–ª—é—Å –∫–æ–Ω–≤–µ–π–µ—Ä –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–º–∞–Ω–¥ –º–æ–∂–µ—Ç –±—ã—Ç—å –∑–∞–≥—Ä—É–∂–µ–Ω –∏–ª–∏ –Ω–µ—Ç –≤ –∑–∞–≤–∏—Å–∏–º–æ—Å—Ç–∏ –æ—Ç –ø—Ä–µ–¥—ã–¥—É—â–∏—Ö –∫–æ–º–∞–Ω–¥. –£ –∫–∏—Ç–∞–π—Ü–µ–≤ –≤—Å–µ –≤—ã–ø–æ–ª–Ω—è–µ—Ç—Å—è —Å ws0, —Ç.–∫. –∫—ç—à–∏—Ä—É–µ—Ç—Å—è –≤ sram. –ò —ç—Ç–æ –¥–µ–π—Å—Ç–≤–∏—Ç–µ–ª—å–Ω–æ —Ç–∞–∫
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
–ö–Ý–ê–ú
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å –∞–≤–≥ 13, 2023 09:44:44 |
|
| –î—Ä—É–≥ –ö–æ—Ç–∞ |
 |
–ö–∞—Ä–º–∞: 139
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 2919
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ß—Ç —è–Ω–≤ 10, 2008 22:01:02
–°–æ–æ–±—â–µ–Ω–∏–π: 24684
–û—Ç–∫—É–¥–∞: –ú–æ—Å–∫–æ–≤—Å–∫–∞—è –æ–±–ª–∞—Å—Ç—å, –§—Ä—è–∑–∏–Ω–æ
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–í–∫—Ä–∞—Ç—Ü–µ: –∫–æ–Ω–≤–µ–π–µ—Ä –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–∞ –ø–∞—Ä–∞–ª–µ–ª–ª–∏–∑—É–µ—Ç –∑–∞–ø—Ä–æ—Å—ã. –ï—Å–ª–∏ —Å–Ω–∞—á–∞–ª–∞ –∑–∞–≥—Ä—É–∑–∏—Ç—å –≤ —Ä–µ–≥–∏—Å—Ç—Ä, –ø–æ—Ç–æ–º –æ–±—Ä–∞–±–∞—Ç—ã–≤–∞—Ç—å, –ø–æ—Ç–æ–º –µ–≥–æ —Å–æ—Ö—Ä–∞–Ω—è—Ç—å - –ø–æ–ª—É—á–∏—Ç—Å—è –¥–æ–ª–≥–∞—è —Ä–∞–±–æ—Ç–∞ –ú—è–≥–∫–æ –≥–æ–≤–æ—Ä—è, –æ—á–µ–Ω—å —Å—Ç—Ä–∞–Ω–Ω–æ–µ –æ–ø–∏—Å–∞–Ω–∏–µ —Ä–∞–±–æ—Ç—ã –∫–æ–Ω–≤–µ–π–µ—Ä–∞...  –í—ã –Ω–µ —Å–º–æ–∂–µ—Ç–µ –≤–æ—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å—Å—è —Å–æ–¥–µ—Ä–∂–∏–º—ã–º —Ä–µ–≥–∏—Å—Ç—Ä–∞ –Ω–∏ –¥–ª—è –∫–∞–∫–∏—Ö —Ü–µ–ª–µ–π —Å—Ä–∞–∑—É –ø–æ—Å–ª–µ –µ–≥–æ –∑–∞–≥—Ä—É–∑–∫–∏. –ü–æ—Ç–æ–º—É —á—Ç–æ "—Å—Ä–∞–∑—É" –Ω–µ —Å—É—â–µ—Å—Ç–≤—É–µ—Ç. –ß—Ç–æ–±—ã —É—Å–∫–æ—Ä–∏—Ç—å —Ä–∞–±–æ—Ç—É, –Ω—É–∂–Ω–æ –º–∞–∫—Å–∏–º–∞–ª—å–Ω–æ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –Ý–û–ù—ã, –∞ –Ω–µ –û–ó–£ –æ–±—â–µ–≥–æ –Ω–∞–∑–Ω–∞—á–µ–Ω–∏—è. –≠—Ç–æ —Ç–∞–∫–∏ RISC-–∞—Ä—Ö–∏—Ç–µ–∫—Ç—É—Ä–∞.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
DmitryKhom
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Ç –∞–≤–≥ 15, 2023 16:41:31 |
|
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 08, 2023 20:38:46
–°–æ–æ–±—â–µ–Ω–∏–π: 4
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
–ù–∞—à–µ–ª –æ—à–∏–±–∫—É —É —Å–µ–±—è: –∑–∞–¥–∞–ª —á–∞—Å—Ç–æ—Ç—É –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–∞ –≤–¥–≤–æ–µ –º–µ–Ω—å—à–µ (144 –ø—Ä–æ—Ç–∏–≤ 288).
–ù–æ —Ä–µ–∑—É–ª—å—Ç–∞—Ç—ã –∏—Å—Å–ª–µ–¥–æ–≤–∞–Ω–∏—è –±—ã–ª–∏ –æ—á–µ–Ω—å –ø–æ–ª–µ–∑–Ω—ã. –Ø –ø–æ–∏–≥—Ä–∞–ª—Å—è —Å –ø–∞–º—è—Ç—å—é, —Å –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–µ–π –∏ –≤–æ—Ç —á—Ç–æ –ø–æ–ª—É—á–∏–ª–æ—Å—å.
–ü–æ–ø—Ä–æ–±–æ–≤–∞–ª –ø–æ–∏–≥—Ä–∞—Ç—å—Å—è —Å –≤–∑—è—Ç–∏–µ–º –∏–∑ –ø–∞–º—è—Ç–∏ - –ø–æ–ª—É—á–∏–ª–æ—Å—å —É–ª—É—á—à–∏—Ç—å. –ü—Ä–∏–º–µ—Ä (R0 = 0x20001A7C, R2 = 0x20001A80, R4 = 0x20001A84):
LDR R1, [R0]
ADD R1, #0
STR R1, [R0]
LDR R3, [R2]
ADD R3, #0
STR R3, [R2]
LDR R5, [R4]
ADD R5, #0
STR R5, [R4]
–≤—ã–ø–æ–ª–Ω—è–µ—Ç—Å—è 49 –Ω—Å (14 —Ç–∞–∫—Ç–æ–≤), –∞ –ø–æ—Å–ª–µ–¥–æ–≤–∞—Ç–µ–ª—å–Ω–æ—Å—Ç—å
LDR R1, [R0]
LDR R3, [R2]
LDR R5, [R4]
ADD R1, #0
STR R1, [R0]
ADD R3, #0
STR R3, [R2]
ADD R5, #0
STR R5, [R4]
–≤—ã–ø–æ–ª–Ω—è–µ—Ç—Å—è 42 –Ω—Å (12 —Ç–∞–∫—Ç–æ–≤).
(–î–∞, —è –º–µ—Ä–∏–ª —Å–≤–æ–∏–º –ª—é–±–∏–º—ã–º GPIO, –Ω–æ –≤—Å–µ —Å—Ö–æ–¥–∏—Ç—Å—è). –í –ø—Ä–∏–Ω—Ü–∏–ø–µ, —Ä–∞–∑–Ω–∏—Ü–∞ –Ω–µ–≤–µ–ª–∏–∫–∞, –Ω–æ –µ—Å—Ç—å.
–î–∞, AT –¥–µ–π—Å—Ç–≤–∏—Ç–µ–ª—å–Ω–æ —Ä–∞–±–æ—Ç–∞–µ—Ç –±—ã—Å—Ç—Ä–µ–µ STM. –ü–æ—ç—Ç–æ–º—É, –µ—Å–ª–∏ —Ä–µ—á—å –∏–¥–µ—Ç –æ–± –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–∏, —Ç–æ –ª—É—á—à–µ, –µ—Å–ª–∏ –±—É–¥–µ—Ç –¥–ª–∏—Ç–µ–ª—å–Ω–∞—è –≤—ã—á–∏—Å–ª–∏—Ç–µ–ª—å–Ω–∞—è —Ü–µ–ø–æ—á–∫–∞.
–¢.–µ. –≤–∑—è–ª –∑–Ω–∞—á–µ–Ω–∏—è - –∏ –¥–æ–ª–≥–æ-–¥–æ–ª–≥–æ –æ–±—Ä–∞–±–∞—Ç—ã–≤–∞–µ—à—å, –ø–æ—Ç–æ–º –∫–ª–∞–¥–µ—à—å.
–ù–æ, –µ—Å–ª–∏ –≥–æ–≤–æ—Ä–∏—Ç—å –æ —Ü–µ–ª–æ—á–∏—Å–ª–µ–Ω–Ω—ã—Ö –≤—ã—á–∏—Å–ª–µ–Ω–∏—è—Ö, —Ç–æ –≤–∑—è—Ç—å –∑–Ω–∞—á–µ–Ω–∏—è –æ—Å–æ–±–æ-—Ç–æ –∏ –Ω–µ–∫—É–¥–∞ - —Ä–µ–≥–∏—Å—Ç—Ä–æ–≤ –≤—Å–µ–≥–æ 12. –ò–Ω–æ–µ –¥–µ–ª–æ –æ–±—Å—Ç–æ–∏—Ç —Å —Ä–µ–≥–∏—Å—Ç—Ä–∞–º–∏ FPU - –∏—Ö 32.
–ù–æ AT —Ä–∞–±–æ—Ç–∞–µ—Ç –±—ã—Å—Ç—Ä–µ–µ! –¢–∞–∫, —è –∑–∞–ø—É—Å—Ç–∏–ª –≤–µ—Å—å –∞–ª–≥–æ—Ä–∏—Ç–º (–±–µ–∑ –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–∏!), –∏ –ø–æ–ª—É—á–∏–ª–æ—Å—å, —á—Ç–æ —ç—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å –≤–æ–∑—Ä–æ—Å–ª–∞ –≥–¥–µ-—Ç–æ –Ω–∞ 30-40 % (—Å–æ–±—Å—Ç–≤–µ–Ω–Ω–æ, –ø—Ä–æ–ø–æ—Ä—Ü–∏–æ–Ω–∞–ª—å–Ω–æ —Ç–∞–∫—Ç–æ–≤–æ–π —á–∞—Å—Ç–æ—Ç–µ - 288/216 –ú–ì—Ü).
–í—ã–≤–æ–¥—ã.
1. AT –Ω–∞ Cortex-M4 —Ä–∞–±–æ—Ç–∞–µ—Ç –±—ã—Å—Ç—Ä–µ–µ –≤–æ –≤—Å–µ—Ö –æ—Ç–Ω–æ—à–µ–Ω–∏—è—Ö, —á–µ–º STM –Ω–∞ Cortex-M7.
2. –û–ø—Ç–∏–º–∏–∑–∞—Ü–∏—è –ø—Ä–∏ —Ü–µ–ª–æ—á–∏—Å–ª–µ–Ω–Ω—ã—Ö –≤—ã—á–∏—Å–ª–µ–Ω–∏—è—Ö –Ω–µ –∏–º–µ–µ—Ç —Å–º—ã—Å–ª–∞ - –º–∞–ª–æ —Ä–µ–≥–∏—Å—Ç—Ä–æ–≤, –¥–∞ –∏ –ø—Ä–æ—Ü–µ—Å—Å, –∫–∞–∫ –ø—Ä–∞–≤–∏–ª–æ, –æ–¥–∏–Ω.
3. –û–ø—Ç–∏–º–∏–∑–∞—Ü–∏—è –ø—Ä–∏ "–ø–ª–∞–≤—É—á–Ω—ã—Ö" –≤—ã—á–∏—Å–ª–µ–Ω–∏—è—Ö –¥–∞—Å—Ç –ø—Ä–µ–≤–æ—Å—Ö–æ–¥–Ω—ã–π —Ä–µ–∑—É–ª—å—Ç–∞—Ç, —Ç.–∫. –µ—Å—Ç—å 32 FPU —Ä–µ–≥–∏—Å—Ç—Ä–∞.
4. –ï—Å–ª–∏ –ø—Ä–æ–≥—Ä–∞–º–º–∞, —Ç—Ä–µ–±—É—é—â–∞—è –±—ã—Å—Ç—Ä–æ–π —Ä–∞–±–æ—Ç—ã (0WS), –¥–æ 512 –∫–ë, —Ç–æ –Ω–µ –Ω–∞–¥–æ –∫—ç—à–∏—Ä–æ–≤–∞—Ç—å –µ–µ, —Å–æ–∑–¥–∞–≤–∞—Ç—å —Å–∏—Å—Ç–µ–º—ã —É–ø—Ä–∞–≤–ª–µ–Ω–∏—è –ø–∞–º—è—Ç—å—é - –æ–Ω–∞ —Å–∞–º–∞ –≥—Ä—É–∑–∏—Ç—Å—è –≤ SRAM –∏ —Ä–∞–±–æ—Ç–∞–µ—Ç –±—ã—Å—Ç—Ä–æ.
5. –¶–µ–Ω–∞ –≥–¥–µ-—Ç–æ –≤ 2-3 —Ä–∞–∑–∞ –Ω–∏–∂–µ —É –∫–∏—Ç–∞–π—Ü–∞.
–Ý–µ–∑—é–º–µ: –≤—ã–±–∏—Ä–∞—é –∫–∏—Ç–∞–π—Ü–∞ AT32F437, –≤—Å—ë –∑–∞–∫–ª–∞–¥—ã–≤–∞—é –ø–æ–¥ –Ω–µ–≥–æ. –ù–æ –¥–µ–ª–∞—é —Ç–∞–∫, —á—Ç–æ–±—ã –º–æ–∂–Ω–æ –±—ã–ª–æ –∑–∞–ø–∞—è—Ç—å STM32F745.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
tonyk
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –°—Ä –∞–≤–≥ 16, 2023 06:10:41 |
|
| –°–≤–µ—Ä–ª–∏—Ç —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç –∫–æ–≥—Ç—è–º–∏ |
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –Ω–æ—è 19, 2019 06:10:18
–°–æ–æ–±—â–µ–Ω–∏–π: 1270
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
DmitryKhom –ø–∏—Å–∞–ª(–∞): –≤—ã–±–∏—Ä–∞—é –∫–∏—Ç–∞–π—Ü–∞ AT32F437, –≤—Å—ë –∑–∞–∫–ª–∞–¥—ã–≤–∞—é –ø–æ–¥ –Ω–µ–≥–æ. –ù–æ –¥–µ–ª–∞—é —Ç–∞–∫, —á—Ç–æ–±—ã –º–æ–∂–Ω–æ –±—ã–ª–æ –∑–∞–ø–∞—è—Ç—å STM32F745 –ù–∞—Å–∫–æ–ª—å–∫–æ —Å–ª–æ–∂–Ω–æ —Ä–µ–∞–ª–∏–∑–æ–≤–∞—Ç—å —Ç–∞–∫–æ–µ? –ú–æ–∂–Ω–æ –ø—Ä–æ–∏–ª–ª—é—Å—Ç—Ä–∏—Ä–æ–≤–∞—Ç—å?
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
DmitryKhom
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å –∞–≤–≥ 20, 2023 01:48:40 |
|
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 08, 2023 20:38:46
–°–æ–æ–±—â–µ–Ω–∏–π: 4
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
DmitryKhom –ø–∏—Å–∞–ª(–∞): –≤—ã–±–∏—Ä–∞—é –∫–∏—Ç–∞–π—Ü–∞ AT32F437, –≤—Å—ë –∑–∞–∫–ª–∞–¥—ã–≤–∞—é –ø–æ–¥ –Ω–µ–≥–æ. –ù–æ –¥–µ–ª–∞—é —Ç–∞–∫, —á—Ç–æ–±—ã –º–æ–∂–Ω–æ –±—ã–ª–æ –∑–∞–ø–∞—è—Ç—å STM32F745 –ù–∞—Å–∫–æ–ª—å–∫–æ —Å–ª–æ–∂–Ω–æ —Ä–µ–∞–ª–∏–∑–æ–≤–∞—Ç—å —Ç–∞–∫–æ–µ? –ú–æ–∂–Ω–æ –ø—Ä–æ–∏–ª–ª—é—Å—Ç—Ä–∏—Ä–æ–≤–∞—Ç—å? –ï—Å–ª–∏ –≥–æ–≤–æ—Ä–∏—Ç—å –ø—Ä–æ –∂–µ–ª–µ–∑–æ. –Ø –∏—Å–ø–æ–ª—å–∑—É—é LQFP144 –≤ —Å–≤–æ–µ–º —Ä–µ—à–µ–Ω–∏–∏. –ù–∞—à–µ–ª —Ä–∞–∑–Ω–∏—Ü—É —Ç–æ–ª—å–∫–æ –≤ –æ–¥–Ω–æ–º –≤—ã–≤–æ–¥–µ ‚Ññ143 - —ç—Ç–æ –Ω–æ–≥–∞ PDR_ON —É STM32 –∏ –æ–Ω–∞ –∂–µ Vss —É AT32. –í –ø–µ—Ä–≤–æ–º —Å–ª—É—á–∞–µ –µ–µ –º–Ω–µ –Ω–∞–¥–æ –∫ +3,3–í, –≤–æ –≤—Ç–æ—Ä–æ–º - –∫ GND. –ü—Ä–∏ —Ç–æ–º, —á—Ç–æ –ø–æ—á—Ç–∏ –≤—Å–µ –Ω–æ–≥–∏ —É –ú–ö –∑–∞–¥–µ–π—Å—Ç–≤–æ–≤–∞–Ω—ã –≤ —Ä–µ—à–µ–Ω–∏–∏! –ï—Å–ª–∏ –≥–æ–≤–æ—Ä–∏—Ç—å –ø—Ä–æ –ø—Ä–æ–≥—Ä–∞–º–º—É. –ë–æ–ª—å—à–∏–Ω—Å—Ç–≤–æ –ø–µ—Ä–∏—Ñ–µ—Ä–∏–∏ —Å–æ–≤–ø–∞–¥–∞–µ—Ç –ø–æ –∞–¥—Ä–µ—Å–∞–º. –ù–æ RCC —É STM –ø–æ—Å—Ç—Ä–æ–µ–Ω –∏–Ω–∞—á–µ, —á–µ–º CRM —É AT; —Å–≤–æ–∏ –æ–≥—Ä–∞–Ω–∏—á–µ–Ω–∏—è –ø–æ —á–∞—Å—Ç–æ—Ç–µ, –Ω–µ–ª—å–∑—è –ø–æ—Å—Ç—Ä–æ–∏—Ç—å EMAC –Ω–∞ –º–∞–∫—Å–∏–º–∞–ª—å–Ω–æ–π —Å–∫–æ—Ä–æ—Å—Ç–∏, –Ω–µ –ø—Ä–∏–±–µ–≥–∞—è –∫ —Å–æ–±—Å—Ç–≤–µ–Ω–Ω–æ–º—É –≥–µ–Ω–µ—Ä–∞—Ç–æ—Ä—É –∏ —Ç.–ø., —É STM –Ω–∞–¥–æ —Å—Ç—Ä–æ–∏—Ç—å —Å–∏—Å—Ç–µ–º—É —É–ø—Ä–∞–≤–ª–µ–Ω–∏—è –ø–∞–º—è—Ç—å—é –¥–ª—è —É—Å–∫–æ—Ä–µ–Ω–∏—è (–∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –∫—ç—à), –≤ —Ç–æ –≤—Ä–µ–º—è –∫–∞–∫ —É AT –ø–æ—á—Ç–∏ –≤—Å—è –ø—Ä–æ–≥—Ä–∞–º–º–∞ —Ç—É–¥–∞ —É–∂–µ –≥—Ä—É–∑–∏—Ç—Å—è, –∏ –∫—ç—à —Å –ø–æ–ª—Ñ–ª—ç—à–∫–∏. –Ø –Ω–µ –∑–∞–¥—É–º—ã–≤–∞–ª—Å—è –æ–± —É–Ω–∏–≤–µ—Ä—Å–∞–ª—å–Ω–æ–π –ø—Ä–æ–≥—Ä–∞–º–º–µ, –∫–æ—Ç–æ—Ä–∞—è –±—ã —Å–∞–º–∞ —Ä–µ—à–∞–ª–∞, –∫–∞–∫–æ–π –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä —Å—Ç–æ–∏—Ç, –Ω–æ –≤ –ø—Ä–∏–Ω—Ü–∏–ø–µ —ç—Ç–æ –≤–æ–∑–º–æ–∂–Ω–æ. –ü–ª—é—Å —è –µ—â–µ –Ω–µ –≤—Å—é –ø–µ—Ä–∏—Ñ–µ—Ä–∏—é –ø–æ—â—É–ø–∞–ª, –ø–æ—ç—Ç–æ–º—É –Ω–µ –≤—Å–µ –ø–æ–¥–≤–æ–¥–Ω—ã–µ –∫–∞–º–Ω–∏ –∏–∑—É—á–∏–ª.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
u37
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å –∞–≤–≥ 20, 2023 11:45:37 |
|
| –≠–ª–µ–∫—Ç—Ä–∏—á–µ—Å–∫–∏–π –∫–æ—Ç |
–ö–∞—Ä–º–∞: 5
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 173
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü–Ω –º–∞–π 01, 2017 20:01:45
–°–æ–æ–±—â–µ–Ω–∏–π: 1080
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ü–µ—Ä–µ—á–∏—Ç–∞–π—Ç–µ –≥–∞–π–¥—ã –ø–æ –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–∏. –≠—Ç–æ –Ω–µ –æ–ø—Ç–∏–º–∞–ª—å–Ω—ã–π –∫–æ–¥ –¥–ª—è –∫–æ–Ω–≤–µ–π–µ—Ä–∞. –ß—Ç–æ-–±—ã –Ω–µ–±—ã–ª–æ –ø–æ—Ç–µ—Ä—å, –º–µ–∂–¥—É –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ–º –æ–¥–Ω–æ–≥–æ –∏ —Ç–æ–≥–æ-–∂–µ —Ä–µ–≥–∏—Å—Ç—Ä–∞ –¥–æ–ª–∂–Ω–æ –ø—Ä–æ–π—Ç–∏ N –¥—Ä—É–≥–∏—Ö –æ–ø–µ—Ä–∞—Ü–∏–π, –≥–¥–µ N = IPC. (—É—Ç—Ä–∏—Ä–æ–≤–∞–Ω–Ω–æ) –î–ª—è –¥–∞–Ω–Ω–æ–≥–æ –ø—Ä–∏–º–µ—Ä–∞ –ª—É—á—à–µ –æ–ø—Ç–∏–º–∏–∑–∏—Ä–æ–≤–∞–Ω–Ω—ã–º –±—É–¥–µ—Ç –≤–∞—Ä–∏–∞–Ω—Ç: –ö–æ–¥: LDR R1, [R0]
LDR R3, [R2]
LDR R5, [R4]
ADD R1, #0
ADD R3, #0
ADD R5, #0
STR R1, [R0]
STR R3, [R2]
STR R5, [R4] –°–º–æ—Ç—Ä–∏—Ç–µ –∏—Å—Ö–æ–¥–Ω–∏–∫–∏ –∫–æ–¥ –¥—Ä—É–≥–∏—Ö –ø—Ä–æ–≥—Ä–∞–º–º, –≤ –∫–æ—Ç–æ—Ä—ã—Ö –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–ª–∞—Å—å –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏—è. –ò—Ç–∞–∫, –≤–∞—Ä–∏–∞–Ω—Ç "–≤—Å—ë –∑–∞–≥—Ä—É–∑–∏—Ç—å" -> "–≤—Å—ë –ø–æ—Å—á–∏—Ç–∞—Ç—å" -> "–≤—Å—ë —Å–æ—Ö—Ä–∞–Ω–∏—Ç—å" —è–≤–ª—è–µ—Ç—Å—è —Ç–∏–ø–æ–≤—ã–º. –£ —Å–µ–±—è –≤ –∫–æ–¥–µ —è –ø–æ–ª—É—á–∞–ª IPC –ø–æ—á—Ç–∏ 3 (2.8, –∫–∞–∂–µ—Ç—Å—è) –∫–∞–∫ –≤—Å–µ–π —Ä–∞–±–æ—Ç—ã –æ—Å–Ω–æ–≤–Ω–æ–≥–æ —Ü–∏–∫–ª–∞, –¥–ª—è x86. –û–ø—Ç–∏–º–∏–∑–∞—Ü–∏—è –ø–æ –≤–∑–∞–∏–º–æ–≤–ª–∏—è–Ω–∏—é —Ä–µ–≥–∏—Å—Ç—Ä–æ–≤ –¥–∞–ª–µ–∫–æ –Ω–µ –≤—Å—ë, —á—Ç–æ —Å–∫–∞–∑—ã–≤–∞–µ—Ç—Å—è –Ω–∞ –ø–æ—Ç–µ—Ä—è—Ö. –ü—Ä–æ–≤–∞–ª–∏—Ç—å —Å–∫–æ—Ä–æ—Å—Ç—å –º–æ–∂–Ω–æ –ø–æ –º–∞—Å—Å–µ –ø—Ä–∏—á–∏–Ω - –Ω–µ –≥—Ä–∞–Ω–Ω—É–ª—è—Ä–Ω–æ –≤—ã–±—Ä–∞–Ω–æ –∫–µ—à–∏—Ä–æ–≤–∞–Ω–∏–µ, —Ä–∞–∑–º–µ—â–µ–Ω–∏–µ –≤ –ø–∞–º—è—Ç–∏ (–ø–æ —Å—Ç—Ä–∞–Ω—Ü–∞–º 4–∫), –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ –Ω–µ—É–¥–∞—á–Ω—ã—Ö –∏–Ω—Å—Ç—Ä—É–∫—Ü–∏–π (–ø–æ—á–µ–º—É —É–¥–∞–ª–∏–ª–∏ –≤—Å–µ–º–∏ –ª—é–±–∏–º—ã–π –æ–ø–µ—Ä–∞—Ç–æ—Ä INC) –∏ —Ç.–¥. –ö–æ–º–ø–∏–ª—è—Ç–æ—Ä –æ–± —ç—Ç–æ–º –∑–Ω–∞–µ—Ç –∏ –º–æ–∂–µ—Ç –ø—Ä–∞–≤–∏–ª—å–Ω–æ –æ–ø—Ç–∏–º–∏–∑–∏—Ä–æ–≤–∞—Ç—å –∫–æ–¥, –∞ "—Ä—É–∫–∞–º–∏" ... –Ω–µ–∞, –∂–∞–ª–∫–∏–µ –ø–æ—Ç—É–≥–∏. –ß—Ç–æ –¥–æ ARM'–∞, —Ç–æ –µ–≥–æ optimization guide –Ω–µ —á–∏—Ç–∞–ª –∏ –Ω–µ –Ω—É–∂–µ–Ω –º–Ω–µ —ç—Ç–æ—Ç –∫–æ—à–º–∞—Ä –Ω–∞ –Ω–æ—á—å. ))
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
>TEHb<
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –°—Ä –∞–≤–≥ 23, 2023 13:35:44 |
|
| –î—Ä—É–≥ –ö–æ—Ç–∞ |
 |
–ö–∞—Ä–º–∞: 17
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 467
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –Ω–æ—è 11, 2009 17:19:30
–°–æ–æ–±—â–µ–Ω–∏–π: 5594
–û—Ç–∫—É–¥–∞: –í–æ—Ä–æ–Ω–µ–∂
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
u37 –ø–∏—Å–∞–ª(–∞): –¥–ª—è x86. u37 –ø–∏—Å–∞–ª(–∞): –ß—Ç–æ –¥–æ ARM'–∞, —Ç–æ –µ–≥–æ optimization guide –Ω–µ —á–∏—Ç–∞–ª –ò –≤–æ—Ç —Ç–∞–∫ –∑–∞–ø—Ä–æ—Å—Ç–æ —Å—Ä–∞–≤–Ω–∏–≤–∞—Ç—å CISC –∏ RISC, –¥–∞ –µ—â—ë –∏ –±–æ–ª—å—à—É—é –º–∞—à–∏–Ω—É —Å –º–∏–∫—Ä–æ–∫–æ–Ω—Ç—Ä–æ–ª–ª–µ—Ä–æ–º? –°–º–µ–ª–æ!
_________________
"–ü—Ä–∏–≤–µ—Ç!" - —Å–æ–≤—Ä–∞–ª –æ–Ω.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
jcxz
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç –∞–≤–≥ 25, 2023 17:42:30 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
–ö–∞—Ä–º–∞: -7
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 188
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 15, 2017 10:51:13
–°–æ–æ–±—â–µ–Ω–∏–π: 1667
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ü–µ—Ä–µ—á–∏—Ç–∞–π—Ç–µ –≥–∞–π–¥—ã –ø–æ –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–∏. –≠—Ç–æ –Ω–µ –æ–ø—Ç–∏–º–∞–ª—å–Ω—ã–π –∫–æ–¥ –¥–ª—è –∫–æ–Ω–≤–µ–π–µ—Ä–∞. –ë—Ä–µ–¥. –í Cortex-M4 –Ω–µ—Ç –Ω–∏–∫–∞–∫–∏—Ö –∫–æ–Ω–≤–µ–µ—Ä–æ–≤. –ß—Ç–æ –¥–æ ARM'–∞, —Ç–æ –µ–≥–æ optimization guide –Ω–µ —á–∏—Ç–∞–ª –∏ –Ω–µ –Ω—É–∂–µ–Ω –º–Ω–µ —ç—Ç–æ—Ç –∫–æ—à–º–∞—Ä –Ω–∞ –Ω–æ—á—å. )) –ö —Ö–∏—Ä—É—Ä–≥—É –≤—ã —Ç–æ–∂–µ –ø—Ä–∏—Ö–æ–¥–∏—Ç–µ —Å —Ñ—Ä–∞–∑–æ–π: "–≠—Ç–∏—Ö –≤–∞—à–∏—Ö –≥–∞–π–¥–æ–≤ –ø–æ —Ö–∏—Ä—É—Ä–≥–∏–∏ —è –Ω–µ —á–∏—Ç–∞–ª, –Ω–æ —Ä–µ–∑–∞—Ç—å –Ω—É–∂–Ω–æ —Ç–∞–∫..." ? 
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–ö–Ý–ê–ú
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç –∞–≤–≥ 25, 2023 21:00:28 |
|
| –î—Ä—É–≥ –ö–æ—Ç–∞ |
|
–ö–∞—Ä–º–∞: 139
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 2919
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ß—Ç —è–Ω–≤ 10, 2008 22:01:02
–°–æ–æ–±—â–µ–Ω–∏–π: 24684
–û—Ç–∫—É–¥–∞: –ú–æ—Å–∫–æ–≤—Å–∫–∞—è –æ–±–ª–∞—Å—Ç—å, –§—Ä—è–∑–∏–Ω–æ
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–í Cortex-M4 –Ω–µ—Ç –Ω–∏–∫–∞–∫–∏—Ö –∫–æ–Ω–≤–µ–µ—Ä–æ–≤. –í–æ–æ–±—â–µ —Ç–æ –µ—Å—Ç—å. 3-stage pipeline. 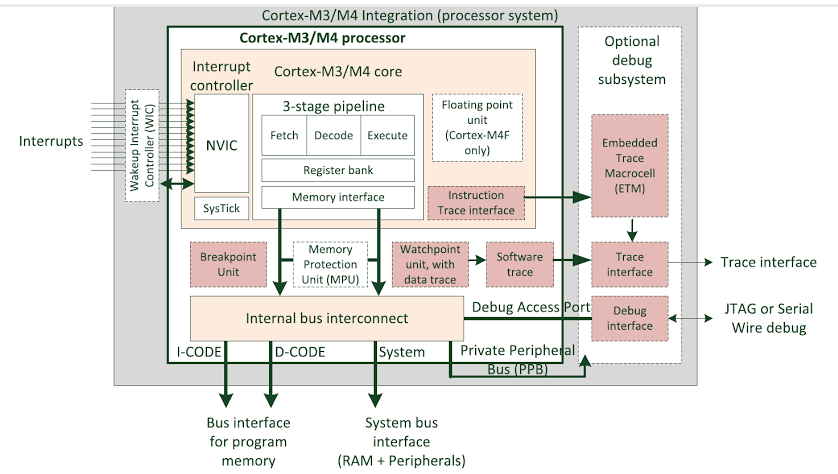
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
jcxz
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: AT32F437: –≠—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã –∫–æ–º–∞–Ω–¥ Cortex-M4 –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –∞–≤–≥ 26, 2023 00:37:50 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
–ö–∞—Ä–º–∞: -7
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 188
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 15, 2017 10:51:13
–°–æ–æ–±—â–µ–Ω–∏–π: 1667
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–í–æ–æ–±—â–µ —Ç–æ –µ—Å—Ç—å.
3-stage pipeline. –≠—Ç–æ –≤–æ–æ–±—â–µ –Ω–µ –æ —Ç–æ–º. –ù–µ—Ç—É —Ç–∞–º –∫–æ–Ω–≤–µ–µ—Ä–∞ —Ç–æ–≥–æ —Ç–∏–ø–∞, –æ –∫–æ—Ç–æ—Ä–æ–º –≤–µ—â–∞–µ—Ç u37. –í CM4 –Ω–µ—Ç –Ω–∏–∫–∞–∫–æ–π —Ä–∞–∑–Ω–∏—Ü—ã –≤ —Å–∫–æ—Ä–æ—Å—Ç–∏, –∏—Å–ø–æ–ª–Ω—è—é—Ç—Å—è –ª–∏ LDR/ADD/STR –¥—Ä—É–≥ –∑–∞ –¥—Ä—É–≥–æ–º –∏–ª–∏ –ø–µ—Ä–µ–º–µ—à–∞–Ω—ã —Å –¥—Ä—É–≥–∏–º–∏ –∫–æ–º–∞–Ω–¥–∞–º–∏ (–∑–∞ –∏—Å–∫–ª—é—á–µ–Ω–∏–µ–º –∏–¥—É—â–∏—Ö –ø–æ–¥—Ä—è–¥ LDR —Å –æ–ø—Ä–µ–¥–µ–ª—ë–Ω–Ω—ã–º–∏ —Ç–∏–ø–∞–º–∏ –∞–¥—Ä–µ—Å–∞—Ü–∏–π). –¢.–µ. - –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ —Å–ª–æ–≤–∞, –∑–∞–≥—Ä—É–∂–µ–Ω–Ω–æ–≥–æ LDR —Å—Ä–∞–∑—É –∂–µ –≤ —Å–ª–µ–¥—É—é—â–µ–π –∫–æ–º–∞–Ω–¥–µ ADD, –Ω–∏–∫–∞–∫ —Å–∞–º–æ –ø–æ —Å–µ–±–µ –Ω–µ —à—Ç—Ä–∞—Ñ—É–µ—Ç—Å—è (–¥–æ–ø–æ–ª–Ω–∏—Ç–µ–ª—å–Ω—ã–º–∏ —Ç–∞–∫—Ç–∞–º–∏). –í –ª—é–±–æ–º —Å–ª—É—á–∞–µ ADD –±—É–¥–µ—Ç = 1 —Ç–∞–∫—Ç. –ö–∞–∫ –∏ —Å–æ—Ö—Ä–∞–Ω–µ–Ω–∏–µ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞ —Å—Ä–∞–∑—É –ø–æ—Å–ª–µ ADD - —Ç–æ–∂–µ –Ω–∏–∫–∞–∫ –Ω–µ —à—Ç—Ä–∞—Ñ—É–µ—Ç—Å—è.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 1 –∏–∑ 1
|
[ –°–æ–æ–±—â–µ–Ω–∏–π: 14 ] |
|
–ö—Ç–æ —Å–µ–π—á–∞—Å –Ω–∞ —Ñ–æ—Ä—É–º–µ |
–°–µ–π—á–∞—Å —ç—Ç–æ—Ç —Ñ–æ—Ä—É–º –ø—Ä–æ—Å–º–∞—Ç—Ä–∏–≤–∞—é—Ç: Kontantin –∏ –≥–æ—Å—Ç–∏: 23 |
|
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –Ω–∞—á–∏–Ω–∞—Ç—å —Ç–µ–º—ã
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –æ—Ç–≤–µ—á–∞—Ç—å –Ω–∞ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —É–¥–∞–ª—è—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –¥–æ–±–∞–≤–ª—è—Ç—å –≤–ª–æ–∂–µ–Ω–∏—è
|
|
|








