|
–§–æ—Ä—É–º –Ý–∞–¥–∏–æ–ö–æ—Ç • –ü—Ä–æ—Å–º–æ—Ç—Ä —Ç–µ–º—ã - –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ
–°–æ–æ–±—â–µ–Ω–∏—è –±–µ–∑ –æ—Ç–≤–µ—Ç–æ–≤ | –ê–∫—Ç–∏–≤–Ω—ã–µ —Ç–µ–º—ã
 
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 2 –∏–∑ 4
|
[ –°–æ–æ–±—â–µ–Ω–∏–π: 71 ] |
, , , |
| –ê–≤—Ç–æ—Ä |
–°–æ–æ–±—â–µ–Ω–∏–µ |
MLX90640

|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ  –î–æ–±–∞–≤–ª–µ–Ω–æ: –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç –æ–∫—Ç 21, 2022 19:54:45 |
|
| –û–ø—ã—Ç–Ω—ã–π –∫–æ—Ç |
 |
–ö–∞—Ä–º–∞: 2
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 164
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –∞–≤–≥ 03, 2022 05:22:56
–°–æ–æ–±—â–µ–Ω–∏–π: 848
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
–ö—Å—Ç–∞—Ç–∏, –µ—â–µ –æ–¥–∏–Ω —Å–ø–æ—Å–æ–± - –≤ —Ü–∏–∫–ª–µ –æ—Ç 0 –¥–æ n –ø—Ä–æ–≤–æ–¥–∏—Ç—å –Ω–∞–∫–æ–ø–ª–µ–Ω–∏–µ –∞–±—Å–æ–ª—é—Ç–Ω–æ–π (–±–µ–∑ —É—á–µ—Ç–∞ –∑–Ω–∞–∫–∞) —Ä–∞–∑–Ω–æ—Å—Ç–∏ —ç–ª–µ–º–µ–Ω—Ç–æ–≤ –º–∞—Å—Å–∏–≤–æ–≤: x += abs(A[n] - B[n]). –í –∫–æ–Ω—Ü–µ —Ü–∏–∫–ª–∞ –ø—Ä–æ–≤–µ—Ä–∏—Ç—å –∑–Ω–∞—á–µ–Ω–∏–µ x. –ï—Å–ª–∏ –æ–Ω–æ –æ—Ç–ª–∏—á–∞–µ—Ç—Å—è –æ—Ç 0, –∑–Ω–∞—á–∏—Ç –º–∞—Å—Å–∏–≤—ã —Ä–∞–∑–Ω—ã–µ –ø–æ –∑–Ω–∞—á–µ–Ω–∏—è–º.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
 |
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
veso74
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç –æ–∫—Ç 21, 2022 20:05:35 |
|
–ö–∞—Ä–º–∞: 25
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 498
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°–± –º–∞–π 05, 2012 20:24:52
–°–æ–æ–±—â–µ–Ω–∏–π: 1852
–û—Ç–∫—É–¥–∞: KN34PC, –ë–æ–ª–≥–∞—Ä–∏—è
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ï—Å–ª–∏ —Å–æ–±–∏—Ä–∞–µ–º—Å—è –ø—Ä–∏–º–µ–Ω—è—Ç—å –º–∞—Ç–µ–º–∞—Ç–∏–∫—É, —Å—É—â–µ—Å—Ç–≤—É–µ—Ç —Å—Ç–æ–ª—å–∫–æ –º–µ—Ç–æ–¥–æ–≤, —Å–∫–æ–ª—å–∫–æ —Ö–æ—Ç–∏–º. –ù–∞–ø—Ä. CRC –¥–∞–∂–µ –≤ –¥–∞—Ç—á–∏–∫–∏ –≤–ª–æ–∂–µ–Ω—ã. –ù–æ –≤—ã—á–∏—Å–ª–∏—Ç–µ–ª—å–Ω–∞—è –º–æ—â–Ω–æ—Å—Ç—å –∫—Ä–æ—à–µ—á–Ω—ã—Ö mcu –∏–¥–µ—Ç –Ω–∞ "–±–µ–∑–∂–∞–ª–æ—Å—Ç–Ω–æ–µ" –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ. –° –ª—é–±–æ–≤—å—é –Ω–∞–ø—Ä. –≤–æ–∑–≤—Ä–∞—â–∞—é—Å—å –∫ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—é, –Ω–∞–ø—Ä. –∫ –ª—é–±. ATtiny13 - —Å–∫–æ–ª—å–∫–æ —Ñ—É–Ω–∫—Ü–∏–π –∏ –º–∞—Ç–µ–º–∞—Ç–∏–∫–∏ –º–æ–∂–Ω–æ —Å–æ–±—Ä–∞—Ç—å, –∞ –æ–±—ä–µ–º –ø–∞–º—è—Ç–∏ –≤—Å–µ —Ä–∞–≤–Ω–æ –Ω–µ –¥–æ—Å—Ç–∏–≥–Ω–µ—Ç  .
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
Eddy_Em
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç –æ–∫—Ç 21, 2022 20:12:02 |
|
| –°–æ–±—É—Ç—ã–ª—å–Ω–∏–∫ –ö–æ—Ç–∞ |
 |
–ö–∞—Ä–º–∞: -12
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: -24
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü—Ç –∏—é–ª 12, 2019 22:52:01
–°–æ–æ–±—â–µ–Ω–∏–π: 2516
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
Прикольно! Я тоже хачю так песать!  Самое убогое, что я видел - инициализация абдуринщиками ЖК-экранчика. Когда нужно толпу команд инициализации переслать, периодически небольшие паузы делать. И китаезы, как обычно, ничего, лучше тупого копипаста на несколько страниц текста, не придумали. Хотя достаточно завести структуру, инициализировать во флеше, а потом в цикле все это УГ пересылать, делая при необходимости нужные паузы…
_________________
Linux rules! Windows must die. –ó–¥—Ä–∞–≤–æ–º—ã—Å–ª—è—â–∏–π —á–µ–ª–æ–≤–µ–∫ –¥–æ–±—Ä–æ–≤–æ–ª—å–Ω–æ –±—É–¥–µ—Ç –ø–æ–ª—å–∑–æ–≤–∞—Ç—å—Å—è –º–∞—Å—Ç–¥–∞–µ–º –ª–∏—à—å –≤ –¥–≤—É—Ö —Å–ª—É—á–∞—è—Ö: –ø–æ–¥ –¥—É–ª–æ–º –∞–≤—Ç–æ–º–∞—Ç–∞ –∏–ª–∏ –ø–æ–¥ –≤–ª–∏—è–Ω–∏–µ–º –∞–Ω–∞–ª—å–Ω–æ–≥–æ –∑–æ–Ω–¥–∞.
–Ø –Ω–∞ –≥–∏—Ç—Ö–∞–±–µ, –≤ –ñ–ñ
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
OKF
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç –æ–∫—Ç 21, 2022 21:39:40 |
|
| –≠—Ç–æ –Ω–µ —Ö–≤–æ—Å—Ç, —ç—Ç–æ –∞–Ω—Ç–µ–Ω–Ω–∞ |
–ö–∞—Ä–º–∞: 12
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 136
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∏—é–Ω 07, 2011 08:03:18
–°–æ–æ–±—â–µ–Ω–∏–π: 1327
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: -2
|
|
–û–π, –¥–∞ –ª–∞–¥–Ω–æ, –¥—è–¥—è! –ê—Ä–¥—É–∏–Ω–æ - —ç—Ç–æ –°++, —Ç—ã –∑—Ç–æ —Ö–∞–≤–∞–µ—à—å? –ò–ª–∏ –ø—Ä–æ—Å—Ç–æ, –∫–∞–∫–æ–π —è —Ç—É—Ç –∫—Ä—É—Ç–æ–π?
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
u37
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 00:48:18 |
|
| –≠–ª–µ–∫—Ç—Ä–∏—á–µ—Å–∫–∏–π –∫–æ—Ç |
–ö–∞—Ä–º–∞: 5
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 173
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü–Ω –º–∞–π 01, 2017 20:01:45
–°–æ–æ–±—â–µ–Ω–∏–π: 1085
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ö—Å—Ç–∞—Ç–∏, –µ—â–µ –æ–¥–∏–Ω —Å–ø–æ—Å–æ–± - –≤ —Ü–∏–∫–ª–µ –æ—Ç 0 –¥–æ n –ø—Ä–æ–≤–æ–¥–∏—Ç—å –Ω–∞–∫–æ–ø–ª–µ–Ω–∏–µ –∞–±—Å–æ–ª—é—Ç–Ω–æ–π (–±–µ–∑ —É—á–µ—Ç–∞ –∑–Ω–∞–∫–∞) —Ä–∞–∑–Ω–æ—Å—Ç–∏ —ç–ª–µ–º–µ–Ω—Ç–æ–≤ –º–∞—Å—Å–∏–≤–æ–≤: x += abs(A[n] - B[n]). –í –∫–æ–Ω—Ü–µ —Ü–∏–∫–ª–∞ –ø—Ä–æ–≤–µ—Ä–∏—Ç—å –∑–Ω–∞—á–µ–Ω–∏–µ x. –ï—Å–ª–∏ –æ–Ω–æ –æ—Ç–ª–∏—á–∞–µ—Ç—Å—è –æ—Ç 0, –∑–Ω–∞—á–∏—Ç –º–∞—Å—Å–∏–≤—ã —Ä–∞–∑–Ω—ã–µ –ø–æ –∑–Ω–∞—á–µ–Ω–∏—è–º. –í–æ-–ø–µ—Ä–≤—ã—Ö, —Ñ—É–Ω–∫—Ü–∏—è "abs" –Ω–µ –±–µ—Å–ø–ª–∞—Ç–Ω–∞—è –∏ –∏–º–µ–µ—Ç —Å—Ö–æ–∂–∏–µ –∑–∞—Ç—Ä–∞—Ç—ã, –∫–∞–∫ –∏ —É "if". –ß—Ç–æ, –≤–æ–æ–±—â–µ, –ª–∏—à–∞–µ—Ç —Å–º—ã—Å–ª–∞. –í–æ-–≤—Ç–æ—Ä—ã—Ö, –Ω–∞ –¥–≤—É—Ö –∞–±—Å–æ–ª—é—Ç–Ω–æ —Ä–∞–∑–Ω—ã—Ö –º–∞—Å—Å–∏–≤–∞—Ö –≤—ã –º–æ–∂–µ—Ç–µ –ø–æ–ª—É—á–∏—Ç—å "0". –û—à–∏–±–∫—É —Å–∞–º–∏ –Ω–∞–π–¥–µ—Ç–µ?
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
VNS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 01:41:38 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
 |
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 236
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü—Ç –¥–µ–∫ 10, 2021 12:48:46
–°–æ–æ–±—â–µ–Ω–∏–π: 1563
–û—Ç–∫—É–¥–∞: –¢—é–º–µ–Ω—å
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ê –∫–∞–∫ ? –û–¥–∏–Ω –∏–∑ —Å–ø–æ—Å–æ–±–æ–≤ —Ç–∞–∫–æ–π... –í–ª–æ–∂–µ–Ω–∏–µ:
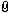 1.png [19.49 KiB]
–°–∫–∞—á–∏–≤–∞–Ω–∏–π: 76
1.png [19.49 KiB]
–°–∫–∞—á–∏–≤–∞–Ω–∏–π: 76
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
MLX90640
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 02:47:13 |
|
| –û–ø—ã—Ç–Ω—ã–π –∫–æ—Ç |
|
–ö–∞—Ä–º–∞: 2
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 164
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –∞–≤–≥ 03, 2022 05:22:56
–°–æ–æ–±—â–µ–Ω–∏–π: 848
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–í–æ-–ø–µ—Ä–≤—ã—Ö, —Ñ—É–Ω–∫—Ü–∏—è "abs" –Ω–µ –±–µ—Å–ø–ª–∞—Ç–Ω–∞—è –∏ –∏–º–µ–µ—Ç —Å—Ö–æ–∂–∏–µ –∑–∞—Ç—Ä–∞—Ç—ã, –í–æ-–ø–µ—Ä–≤—ã—Ö, –∑–Ω–∞–µ—Ç–µ, –∫–∞–∫ –≤—ã—Ä–∞–∂–∞–µ—Ç—Å—è —Ä–∞–∑–Ω–æ—Å—Ç—å –≤ —Ñ–æ—Ä–º–∞—Ç–µ unsigned? –ú–∞—Ç–µ–º–∞—Ç–∏–∫—É –Ω–∞–¥–æ —Ö–æ—Ç—å –Ω–µ–º–Ω–æ–≥–æ —Ç–æ –∑–Ω–∞—Ç—å –í–æ-–≤—Ç–æ—Ä—ã—Ö, –Ω–∞ –¥–≤—É—Ö –∞–±—Å–æ–ª—é—Ç–Ω–æ —Ä–∞–∑–Ω—ã—Ö –º–∞—Å—Å–∏–≤–∞—Ö –≤—ã –º–æ–∂–µ—Ç–µ –ø–æ–ª—É—á–∏—Ç—å "0". –û—à–∏–±–∫—É —Å–∞–º–∏ –Ω–∞–π–¥–µ—Ç–µ? –í–æ-–≤—Ç–æ—Ä—ã—Ö, —è–∂ –Ω–∞–ø–∏—Å–∞–ª - —Ä–∞–∑–Ω–æ—Å—Ç—å –ø–æ –º–æ–¥—É–ª—é, –±–µ–∑ —É—á–µ—Ç–∞ –∑–Ω–∞–∫–∞ —Ç–æ –µ—Å—Ç—å. –ù–∞–∫–æ–ø–ª–µ–Ω–∏–µ —ç—Ç–æ–π —Ä–∞–∑–Ω–æ—Å—Ç–∏. –ï—Å–ª–∏ —Ö–æ—Ç—è–±—ã –æ–¥–∏–Ω —ç–ª–µ–º–µ–Ω—Ç –æ—Ç–ª–∏—á–∞–µ—Ç—Å—è –≤ –º–∞—Å—Å–∏–≤–∞—Ö, —Ç–æ —Ä–∞–∑–Ω–æ—Å—Ç—å —É–∂–µ –Ω–µ –±—É–¥–µ—Ç –Ω—É–ª–µ–≤–æ–π. –∞ –µ—Å–ª–∏ –≤—Ç–æ—Ä–æ–π —ç–ª–µ–º–µ–Ω—Ç –æ—Ç–ª–∏—á–∞–µ—Ç—Å—è –≤ –¥—Ä—É–≥—É—é —Å—Ç–æ—Ä–æ–Ω—É, —Ç–æ —Ä–∞–∑–Ω–æ—Å—Ç—å –ø–æ –º–æ–¥—É–ª—é –Ω–µ –±—É–¥–µ—Ç –æ—Ç—Ä–∏—Ü–∞—Ç–µ–ª—å–Ω–æ–π –∏ –Ω–∞–∫–æ–ø–ª–µ–Ω–∏–µ —Ä–∞–∑–Ω–æ—Å—Ç–∏ –Ω–µ –æ–±–Ω—É–ª–∏—Ç—Å—è.
–ü–æ—Å–ª–µ–¥–Ω–∏–π —Ä–∞–∑ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞–ª–æ—Å—å MLX90640 –°–± –æ–∫—Ç 22, 2022 07:57:59, –≤—Å–µ–≥–æ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞–ª–æ—Å—å 1 —Ä–∞–∑.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
u37
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 07:57:26 |
|
| –≠–ª–µ–∫—Ç—Ä–∏—á–µ—Å–∫–∏–π –∫–æ—Ç |
–ö–∞—Ä–º–∞: 5
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 173
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü–Ω –º–∞–π 01, 2017 20:01:45
–°–æ–æ–±—â–µ–Ω–∏–π: 1085
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
... –æ—à–∏–±–∫–∏ MLX90640 –∏—Å–∫–∞—Ç—å –Ω–µ —Å–æ–±–∏—Ä–∞–µ—Ç—Å—è, –∞ —Å–≤–æ–π –≤–æ–∑—Ä–∞—Å—Ç –ø—Ä–æ–¥–µ–º–æ–Ω—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω –æ—á–µ–Ω—å —á–µ—Ç–∫–æ. –ù–∞ —Å—ë–º —Ä–∞–∑–≥–æ–≤–æ—Ä –∑–∞–∫–æ–Ω—á–µ–Ω.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
MLX90640
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 08:00:01 |
|
| –û–ø—ã—Ç–Ω—ã–π –∫–æ—Ç |
|
–ö–∞—Ä–º–∞: 2
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 164
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –∞–≤–≥ 03, 2022 05:22:56
–°–æ–æ–±—â–µ–Ω–∏–π: 848
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 2
|
u37, –Ø —Ç–∞–º –ø–æ—è—Å–Ω–∏–ª –¥–ª—è –≤–∞—Å, –¥–∞–∂–µ –∫–∞–∫ –¥–ª—è —à–∫–æ–ª—å–Ω–∏–∫–∞, —Å—É—Ç—å –º–æ–¥—É–ª—è —Ä–∞–∑–Ω–æ—Å—Ç–∏ - —ç—Ç–æ –ø—Ä–æ—Å—Ç–æ —Ä–∞—Å—Å—Ç–æ—è–Ω–∏–µ –º–µ–∂–¥—É –¥–≤—É–º—è —Ç–æ—á–∫–∞–º–∏ –±–µ–∑ —É—á–µ—Ç–∞ –Ω–∞–ø—Ä–∞–≤–ª–µ–Ω–∏—è. –≠—Ç–∞ —Ä–∞–∑–Ω–æ—Å—Ç—å –≤—Å–µ–≥–¥–∞ –ø–æ–ª–æ–∂–∏—Ç–µ–ª—å–Ω–∞. –¢–∞–∫ —á—Ç–æ –∏—â–∏—Ç–µ –æ—à–∏–±–∫–∏ –≤ —Å–≤–æ–µ–π –º–∞—Ç–µ–º–∞—Ç–∏–∫–µ –∑–∞ 5 –∫–ª–∞—Å—Å –í–æ—Ç —á—Ç–æ –∑–∞ –º–∞–Ω–µ—Ä–∞ –Ω–∞ —ç—Ç–æ–º —Ñ–æ—Ä—É–º–µ - —á—É—Ç—å —á–æ, –Ω–µ —Ä–∞–∑–æ–±—Ä–∞–≤—à–∏—Å—å –≤ –≤–æ–ø—Ä–æ—Å–µ, —Å—Ä–∞–∑—É –æ–±–≤–∏–Ω—è—Ç—å –≤ –æ—à–∏–±–∫–∞—Ö –∏ —É–ø–æ—Ä–Ω–æ –Ω–µ –∂–µ–ª–∞—Ç—å —Ä–∞–∑–æ–±—Ä–∞—Ç—å—Å—è –≤ —Å—É—Ç–∏. –ù–µ–¥–∞–≤–Ω–æ —ç—Ç–æ—Ç, –∫–∞–∫ –µ–≥–æ —Ç–∞–º, Demiurg, —Å –ø–µ–Ω–æ–π —É —Ä—Ç–∞ –¥–æ–∫–∞–∑—ã–≤–∞–ª, –∫–∞–∫ –Ω–∞–¥–æ —Ñ—É–Ω–∫—Ü–∏–∏ –ø–∏—Å–∞—Ç—å, –∏ —Ç–æ–∂–µ —Å—Å—ã–ª–∞–ª—Å—è –Ω–∞ –≤–æ–∑—Ä–∞—Å—Ç. –ê —Ç–µ–ø–µ—Ä—å –≤–æ—Ç –∏ u37 –¥–æ–∫–∞–∑—ã–≤–∞–µ—Ç —Å–≤–æ–∏ –Ω–µ–∑–Ω–∞–Ω–∏—è —à–∫–æ–ª—å–Ω–æ–π –º–∞—Ç–µ–º–∞—Ç–∏–∫–∏ –∑–∞ 5 –∫–ª–∞—Å—Å –ù—É –∏ –ø–æ –∞–Ω–∞–ª–æ–≥–∏–∏ —Å Demiurg-–æ–º, –¥–∞–≤–∞–π—Ç–µ —Ä–∞–∑–±–µ—Ä–µ–º, —á—Ç–æ –≤—ã, u37 —Ç—É—Ç –ø–æ–Ω–∞–ø–∏—Å–∞–ª–∏: –¶–∏—Ç–∞—Ç–∞: –ö–æ–¥: int cmp=0;
for (.... +4)
{ cmp |=(r1[i] ^ r2[i]) | (r1[i+1] ^ r2[i+1]) | (r1[i+2] ^ r2[i+2]) | (r1[i+3] ^ r2[i+3]); }
if (cmp == 0) ... –í–∞—Å –∏—Å—Ç –¥–∞—Å, —á—Ç–æ –µ—Å—Ç—å —ç—Ç–æ? –ü–æ—è—Å–Ω–∏—Ç–µ —Ö–æ–¥ –≤–∞—à–∏—Ö –º—ã—Å–ª–µ–π. –ó–∞—á–µ–º +4, –ø–æ—á–µ–º—É i+3, —á—Ç–æ —Ç–∞–∫–æ–µ | –∏ –¥–ª—è —á–µ–≥–æ –æ–Ω–æ–µ? –ò –∑–∞—á–µ–º –¥–µ–ª–∏—Ç–µ —ç–ª–µ–º–µ–Ω—Ç—ã –º–∞—Å—Å–∏–≤–∞ –ø–æ 4 —à—Ç—É–∫–∏? –ê –µ—Å–ª–∏ –º–∞—Å—Å–∏–≤—ã –Ω–µ –∫—Ä–∞—Ç–Ω—ã–µ —á–∏—Å–ª—É 4? –ê –º–æ–∂–µ—Ç —Å—Ä–∞–∑—É –≤ –æ–¥–Ω—É –ª–∏–Ω–µ–π–∫—É 40 —à—Ç—É–∫ –∑–∞–ø–∏—Å–∞—Ç—å? –ò–ª–∏ –≤—Å–µ-—Ç–∞–∫–∏ –ø–æ –æ–¥–Ω–æ–º—É? –ï—Å–ª–∏ –¥–µ–ª–∞–µ—Ç–µ –ª–æ–≥–∏—á–µ—Å–∫–∏–º —Å—Ä–∞–≤–Ω–µ–Ω–∏–µ–º –ø–æ xor, —Ç–æ –Ω–µ–∑–∞—á–µ–º –¥–µ–ª–∏—Ç—å –º–∞—Å—Å–∏–≤ –Ω–∞ –≥—Ä—É–ø–ø—ã –ø–æ 4 —à—Ç—É–∫–∏. –°–µ–π –≥–ª—É–±–æ–∫–∏–π —Å–º—ã—Å–µ–ª –∏–∑–ª–∏—à–µ–Ω. –°–¥–µ–ª–∞–π—Ç–µ –ø—Ä–æ—Å—Ç–æ xor –ø–æ –æ–¥–Ω–æ–º—É —ç–ª–µ–º–µ–Ω—Ç—É –∏–∑ –∫–∞–∂–¥–æ–≥–æ –º–∞—Å—Å–∏–≤–∞ –∏ –Ω–µ –º—É–¥—Ä–∏—Ç–µ.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
VNS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 10:19:31 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
|
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 236
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü—Ç –¥–µ–∫ 10, 2021 12:48:46
–°–æ–æ–±—â–µ–Ω–∏–π: 1563
–û—Ç–∫—É–¥–∞: –¢—é–º–µ–Ω—å
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
MLX90640Вам бы "семикласснику", манерам общения стоило бы поучиться…  или Вы с пелёнок кипятком писаете? Свои ранее плюсы убрал, так как видимо не на пользу пошли…  бревна в своём глазу не замечаете? Вопрос риторический, если что… базар разводить не буду...
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
Jack_A
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 11:43:01 |
|
| –î—Ä—É–≥ –ö–æ—Ç–∞ |
 |
–ö–∞—Ä–º–∞: 62
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 889
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–ø—Ä 24, 2007 07:45:40
–°–æ–æ–±—â–µ–Ω–∏–π: 6238
–û—Ç–∫—É–¥–∞: Minsk
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 3
|
—Ä–∞—Å—Å—Ç–æ—è–Ω–∏–µ –º–µ–∂–¥—É –¥–≤—É–º—è —Ç–æ—á–∫–∞–º–∏ –±–µ–∑ —É—á–µ—Ç–∞ –Ω–∞–ø—Ä–∞–≤–ª–µ–Ω–∏—è. –≠—Ç–∞ —Ä–∞–∑–Ω–æ—Å—Ç—å –≤—Å–µ–≥–¥–∞ –ø–æ–ª–æ–∂–∏—Ç–µ–ª—å–Ω–∞. –ß–∏—Å—Ç–æ –º–∞—Ç–µ–º–∞—Ç–∏—á–µ—Å–∫–∏ - –¥–∞. –ù–æ –ø—Ä–∏ —Ä–µ–∞–ª–∏–∑–∞—Ü–∏–∏ –Ω–∞ –ú–ö... –î–æ—Å—á–∏—Ç–∞–ª–∏ –¥–æ 256 - –∏ –ø–ª—É—á–∏–ª–∏ 0. –î–ª—è —Ä–∞–∑–Ω–æ—Å—Ç–∏ –º–∞–ª–æ –æ–¥–Ω–æ–≥–æ –±–∞–π—Ç–∞? –ë–µ—Ä—ë–º –º–∏–Ω–∏–º—É–º 2 ? –¢–æ–≥–¥–∞: —Ä–∞—Å—à–∏—Ä–µ–Ω–∏–µ –ø–µ—Ä–≤–æ–≥–æ –±–∞–π—Ç–∞-–æ–ø–µ—Ä–∞–Ω–¥–∞ –¥–æ —Ü–µ–ª–æ–≥–æ —Å–ª–æ–≤–∞, –ø–æ—Ç–æ–º –≤—Ç–æ—Ä–æ–≥–æ, –ø–æ—Ç–æ–º —Ä–∞–∑–Ω–æ—Å—Ç—å. –≠—Ç–æ –æ—Ç–Ω—é–¥—å –Ω–µ 1 –º–∞—à–∏–Ω–Ω–∞—è –∫–æ–º–∞–Ω–¥–∞ –≤ —Ü–∏–∫–ª–µ. –í –æ–±—â–µ–º, –ø–æ–∫–∞ –∫–æ–Ω–∫—É—Ä–µ–Ω—Ç–∞ –º–æ–µ–π —Ä–µ–∞–ª–∏–∑–∞—Ü–∏–∏ –Ω–µ –≤–∏–∂—É. –ò —á–µ–≥–æ —ç—Ç–æ –º–Ω–æ–≥–∏–µ –∫–∞–∫ —á—ë—Ä—Ç –ª–∞–¥–∞–Ω–∞ –±–æ—è—Ç—Å—è –∞—Å–º–∞, —Ö–æ—Ç—è –±—ã –Ω–∞ —É—Ä–æ–≤–Ω–µ –≤—Å—Ç–∞–≤–∫–∏? "–£ –º–µ–Ω—è –ø–∞–º—è—Ç–∏ –¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ, –Ω–∞ —Ñ—Ä–µ–Ω –º–Ω–µ –≤–∞—à –∞—Å–º. –ù–æ –≤–æ—Ç –ø–æ—á–µ–º—É –æ–Ω–æ —Ç–∞–∫ –º–µ–¥–ª–µ–Ω–Ω–æ —Ä–∞–±–æ—Ç–∞–µ—Ç?!"
_________________

–ü–æ—Å–ª–µ–¥–Ω–∏–π —Ä–∞–∑ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞–ª–æ—Å—å Jack_A –°–± –æ–∫—Ç 22, 2022 18:07:40, –≤—Å–µ–≥–æ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞–ª–æ—Å—å 1 —Ä–∞–∑.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
VladislavS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 12:56:26 |
|
| –°–æ–±—É—Ç—ã–ª—å–Ω–∏–∫ –ö–æ—Ç–∞ |
 |
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 433
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –º–∞–π 01, 2018 19:44:47
–°–æ–æ–±—â–µ–Ω–∏–π: 2557
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ò —á–µ–≥–æ —ç—Ç–æ –º–Ω–æ–≥–∏–µ –∫–∞–∫ —á—ë—Ä—Ç –ª–∞–¥–∞–Ω–∞ –±–æ—è—Ç—Å—è –∞—Å–º–∞, —Ö–æ—Ç—è –±—ã –Ω–∞ —É—Ä–æ–≤–Ω–µ –≤—Å—Ç–∞–≤–∫–∏? –ü–æ–∫–∞ –Ø–í–£ —Å–ø—Ä–∞–≤–ª—è–µ—Ç—Å—è —Å –∑–∞–¥–∞—á–µ–π, –∞—Å–º –∑–ª–æ. –ê—Ä–≥—É–º–µ–Ω—Ç—ã –≤—Å—ë —Ç–µ –∂–µ –∏ —É–∂–µ –¥–µ—Å—è—Ç–∫–∏ –ª–µ—Ç –Ω–µ –º–µ–Ω—è—é—Ç—Å—è: —Ç—Ä—É–¥–æ—ë–º–∫–æ—Å—Ç—å –∏ —Å–æ–≤–º–µ—Å—Ç–∏–º–æ—Å—Ç—å. "–£ –º–µ–Ω—è –ø–∞–º–µ—Ç–∏ –¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ, –Ω–∞ —Ñ—Ä–µ–Ω –º–Ω–µ –≤–∞—à –∞—Å–º. –ù–æ –≤–æ—Ç –ø–æ—á–µ–º—É –æ–Ω–æ —Ç–∞–∫ –º–µ–¥–ª–µ–Ω–Ω–æ —Ä–∞–±–æ—Ç–∞–µ—Ç?!" –í–æ—Ç –∫–æ–≥–¥–∞ –±—É–¥–µ—Ç –º–µ–¥–ª–µ–Ω–Ω–æ —Ä–∞–±–æ—Ç–∞—Ç—å, —Ç–æ–≥–¥–∞ –∏ —Å—Ç–æ–∏—Ç –Ω–∞–π—Ç–∏ —É–∑–∫–æ–µ –º–µ—Å—Ç–æ –∏ –æ–ø—Ç–∏–º–∏–∑–∏—Ä–æ–≤–∞—Ç—å –∏–º–µ–Ω–Ω–æ –µ–≥–æ. –¢—ã–∫–∞—Ç—å –∞—Å–º –∫—É–¥–∞ –Ω–∏ –ø–æ–ø–∞–¥—è –ø–ª–æ—Ö–∞—è –∏–¥–µ—è. –î–æ–±–∞–≤–ª–µ–Ω–æ after 2 minutes 39 seconds:–í –æ–±—â–µ–º, –ø–æ–∫–∞ –∫–æ–Ω–∫—É—Ä–µ–Ω—Ç–∞ –º–æ–µ–π —Ä–µ–∞–ª–∏–∑–∞—Ü–∏–∏ –Ω–µ –≤–∏–∂—É. –ì–¥–µ –º–æ–∂–Ω–æ –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å –≤–∞—à—É —Ä–µ–∞–ª–∏–∑–∞—Ü–∏—é?
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
Jack_A
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 18:06:40 |
|
| –î—Ä—É–≥ –ö–æ—Ç–∞ |
|
–ö–∞—Ä–º–∞: 62
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 889
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–ø—Ä 24, 2007 07:45:40
–°–æ–æ–±—â–µ–Ω–∏–π: 6238
–û—Ç–∫—É–¥–∞: Minsk
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ì–¥–µ –º–æ–∂–Ω–æ –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å –≤–∞—à—É —Ä–µ–∞–ª–∏–∑–∞—Ü–∏—é? –î—ã–∫ —É –º–µ–Ω—è –æ–Ω–æ - –Ω–∞ —É—Ä–æ–≤–Ω–µ –∏–¥–µ–∏  (–ø–æ—Å—Ç –æ—Ç 21.10) –ê —Ç–∞–∫ –ø—Ä–∏–±–ª–∏–∑–∏—Ç–µ–ª—å–Ω–æ –≤—ã–≥–ª—è–¥–µ–ª–æ –±—ã: –ö–æ–¥: LDI ZL,low(Array1)
LDI ZH,highArray1)
LDI YL,low(Array2)
LDI YH,high(Array2)
lab: ld R16,z+
ld R1,y+
sub R16.R1
brne out_cycle
cpi ZH,high(Array1+40)
brlo lab
cpi ZL,low(Array1+40)
brlo lab
out_cycle: tst R16 ; –≤–æ—Ç —Å—é–¥–∞ –º—ã –ø—Ä–∏–¥—ë–º —Å 0 –≤ R16 , –µ—Å–ª–∏ –º–∞—Å—Å–∏–≤—ã —Å–æ–≤–ø–∞–ª–∏ :))
–ï—Å–ª–∏ –±—ã –º–∞—Å—Å–∏–≤—ã –±—ã–ª–∏ –≤ –æ–¥–Ω–æ–º 256-–±–∞–π—Ç–æ–≤–æ–º —Å–µ–≥–º–µ–Ω—Ç–µ, –±—ã–ª–æ –±—ã –µ—â—ë –ø—Ä–æ—â–µ - –Ω–µ –ø—Ä–æ–≤–µ—Ä—è–ª–∏ –±—ã ZH, –Ω–æ –∫–æ–º–ø–∏–ª–µ–≤–∏—á –Ω–∞–º —ç—Ç–æ –Ω–µ –≥–∞—Ä–∞–Ω—Ç–∏—Ä—É–µ—Ç. –ü–æ–ª–Ω–æ—Å—Ç—å—é —Å–æ–≥–ª–∞—Å–µ–Ω - –∞—Å–º –ø–∏—Ö–∞—Ç—å –∫—É–¥–∞ –Ω–∏ –ø–æ–ø–∞–¥—è - –ø–ª–æ—Ö–∞—è –∏–¥–µ—è, –ø—Ä–∏ —ç—Ç–æ–º - –Ω–µ –º–æ—è –ù–æ –µ—Å–ª–∏ –Ω–∞–¥–æ, —Ç–æ... –ò –Ω–µ–ø–æ–Ω—è—Ç–Ω–∞ —Ö–æ—Ç–µ–ª–∫–∞ –¢–° –Ω–∞—Å—á—ë—Ç "–ª–∞–∫–æ–Ω–∏—á–Ω–æ—Å—Ç–∏" - –≤ –ú–ö –Ω–µ –ª–µ–∑–µ—Ç? –±—ã—Å—Ç—Ä–æ–¥–µ–π—Å—Ç–≤–∏—è –Ω–µ —Ö–≤–∞—Ç–∞–µ—Ç? –∏–ª–∏ –º–µ—Å—Ç–∞ –Ω–∞ –¥–∏—Å–∫–µ –∫–æ–º–ø–∞ –≤ –¥–∏—Ä–µ–∫—Ç–æ—Ä–∏–∏ MY_PROJECTS ? ---------- –ü—ã–°—ã –î–∞–≤–Ω–æ –Ω–µ –ø–∏—Å–∞–ª –Ω–∞ –∞—Å–º–µ, —Ç–∞–º, –∫–∞–∂–µ—Ç—Å—è –≤ LDI –Ω–∞ 2 —É–º–Ω–æ–∂–∞—Ç—å –Ω–∞–¥–æ 
_________________
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
VladislavS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 20:58:57 |
|
| –°–æ–±—É—Ç—ã–ª—å–Ω–∏–∫ –ö–æ—Ç–∞ |
|
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 433
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –º–∞–π 01, 2018 19:44:47
–°–æ–æ–±—â–µ–Ω–∏–π: 2557
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ù—É, –¥–∞–≤–∞–π—Ç–µ –ø–æ—Å–º–æ—Ç—Ä–∏–º. –î–æ—Å—Ç–∞—Ç–æ—á–Ω–æ –Ω–µ—Å–ª–æ–∂–Ω–æ –∏—â–µ—Ç—Å—è –∫–æ–¥ memcmp –∏–∑ Microsoft CRT, –∫–æ—Ç–æ—Ä—ã–π —Å–ª–µ–≥–∫–∞ –∏–∑–±—ã—Ç–æ—á–µ–Ω –ø–æ–¥ –∑–∞–¥–∞—á—É –¢–°. –ò–ª–∏ –Ω–∞–ø–∏—à–µ–º –ø—Ä—è–º–æ –≤ –ª–æ–± —Å–∞–º–∏. –ù–∏—á–µ–º –Ω–µ —Ö—É–∂–µ –∏ –≥–∞—Ä–∞–Ω—Ç–∏—Ä–æ–≤–∞–Ω–æ —Ä–∞–±–æ—Ç–∞–µ—Ç, –¥–∞ –µ—â—ë –Ω–∞ –ª—é–±–æ–º –∫–æ–º–ø–∏–ª—è—Ç–æ—Ä–µ –∏ –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–µ. –ê –µ—Å–ª–∏ –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏—é -O3 –ø–æ—Å—Ç–∞–≤–∏—Ç—å, —Ç–æ –µ—â—ë –∏ –±—ã—Å—Ç—Ä–µ–µ –≤–∞—à–µ–≥–æ –≤–∞—Ä–∏–∞–Ω—Ç–∞. –¢–∞–∫ —á—Ç–æ, –ø–æ–±–µ–¥—É –≤—ã —Å–µ–±–µ —Ä–∞–Ω–æ–≤–∞—Ç–æ –ø—Ä–∏–ø–∏—Å–∞–ª–∏.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
Jack_A
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 21:25:50 |
|
| –î—Ä—É–≥ –ö–æ—Ç–∞ |
|
–ö–∞—Ä–º–∞: 62
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 889
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–ø—Ä 24, 2007 07:45:40
–°–æ–æ–±—â–µ–Ω–∏–π: 6238
–û—Ç–∫—É–¥–∞: Minsk
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ò–Ω—Ç–µ—Ä–µ—Å–Ω–æ –±—ã –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å —Å–≥–µ–Ω–µ—Ä–∏—Ä–æ–≤–∞–Ω–Ω—ã–π –∫–æ–¥ —Å –µ–Ω—Ç–æ–π —Å–∞–º–æ–π –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏—é -O3. –Ø –Ω–µ –ø—Ä–µ–¥—Å—Ç–∞–≤–ª—è—é, –∫–∞–∫ –º–æ–∂–Ω–æ –∫–æ—Ä–æ—á–µ - —É –º–µ–Ω—è –Ω–∏ –æ–¥–Ω–æ–π –ª–∏—à–Ω–µ–π –æ–ø–µ—Ä–∞—Ü–∏–∏. –ö–∞–∫ —è —É–∂–µ –≤—ã—Ä–∞–∑–∏–ª—Å—è, –±—ã—Å—Ç—Ä–µ–µ –º–æ–∂–Ω–æ —Ç–æ–ª—å–∫–æ –µ—Å–ª–∏ –æ–±–∞ –º–∞—Å—Å–∏–≤–∞ –Ω–∞—Ö–æ–¥—è—Ç—Å—è –≤ –æ–¥–Ω–æ–π "—Å—Ç—Ä–∞–Ω–∏—Ü–µ" –ø–∞–º—è—Ç–∏ (–º–æ–∂–Ω–æ - –∫–∞–∂–¥—ã–π –≤ —Å–≤–æ–µ–π), —Ç–æ–≥–¥–∞ –Ω–µ –Ω—É–∂–Ω–æ –ø—Ä–æ–≤–µ—Ä—è—Ç—å ZH –Ω–∞ –∫–æ–Ω–µ—Ü —Ü–∏–∫–ª–∞. –Ø –¥–ª—è –ú–ö –Ω–∞ –°–∏ –Ω–µ –ø–∏—Å–∞'–ª –Ω–∏–∫–æ–≥–¥–∞, –ø–æ—ç—Ç–æ–º—É –Ω–µ –∑–Ω–∞—é - –º–æ–∂–Ω–æ –ª–∏ –∑–∞—Å—Ç–∞–≤–∏—Ç—å –∫–æ–º–ø–∞–π–ª–µ—Ä —Ä–∞–∑–º–µ—â–∞—Ç—å –º–∞—Å—Å–∏–≤ –Ω–∞ –≥—Ä–∞–Ω–∏—Ü–µ –±–ª–æ–∫–∞. –ò–ª–∏, –º–æ–∂–µ—Ç –±—ã—Ç—å, –°–∏ - —è–∑—ã–∫ –Ω–∞—Å—Ç–æ–ª—å–∫–æ –≤—ã—Å–æ–∫–æ–≥–æ —É—Ä–æ–≤–Ω—è, —á—Ç–æ –≥–µ–Ω–µ—Ä–∏—Ä—É–µ—Ç —Å–µ–∫—Ä–µ—Ç–Ω—ã–µ —Å—É–ø–µ—Ä–±—ã—Å—Ç—Ä—ã–µ –∫–æ–º–∞–Ω–¥—ã, –Ω–µ–¥–æ—Å—Ç—É–ø–Ω—ã–µ –∞—Å—Å–µ–º–±–ª–µ—Ä—É ? –ê —Ç–æ –ø–æ–ª—É—á–∞–µ—Ç—Å—è - –º–æ–π —Ä–µ–∫–æ—Ä–¥ –ø—ã—Ç–∞—é—Ç—Å—è –æ–ø–æ—Ä–æ—á–∏—Ç—å –±–µ–∑–¥–æ–∫–∞–∑–∞—Ç–µ–ª—å–Ω—ã–º "–º–æ–∂–µ—Ç –±—ã—Ç—å..." ---------- –ù–∞—Å—á—ë—Ç —Å—Å—ã–ª–æ–∫. –ü–µ—Ä–≤–∞—è - –∫–∞–∫–æ–µ –æ—Ç–Ω–æ—à–µ–Ω–∏–µ –∏–º–µ–µ—Ç –ú–µ–ª–∫–æ—Å–æ—Ñ—Ç –∫ –ê—Ç–º–µ–ª –∏ –ø–æ—á–µ–º—É –≤ –Ω—ë–º –¥–æ–ª–∂–Ω—ã –±—ã—Ç—å –∫–æ–¥—ã AVR? –ú–æ–∂–µ—Ç, –≥–¥–µ-—Ç–æ –≤ –Ω—ë–º —á—Ç–æ-—Ç–æ –∏ –≥–ª—É–±–æ–∫–æ —É–ø—Ä—è—Ç–∞–Ω–æ –ø–æ —ç—Ç–æ–π —Ç–µ–º–µ, –Ω–æ –≤–≤–∏–¥—É –ø–æ–∑–¥–Ω–µ–≥–æ –≤ —Ä–µ–º–µ–Ω–∏ –∏ –æ–Ω–æ_–º–Ω–µ_–Ω–∞–¥–æ? –∏—Å–∫–∞—Ç—å –Ω–µ —Å—Ç–∞–ª. –ü–æ –≤—Ç–æ—Ä–æ–π —Å—Å—ã–ª–∫–µ. –ù–∞ –º–æ–π –≤–∑–≥–ª—è–¥, –∫–æ–¥ –¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ –º—É—Ç–Ω—ã–π, –∏—Å–ø–æ–ª—å–∑—É–µ—Ç —Ç—É–µ–≤—É —Ö—É—á—É —Ä–µ–≥–∏—Å—Ç—Ä–æ–≤, –æ–±—ä—ë–º –±–æ–ª—å—à–µ –º–æ–µ–≥–æ –∏ —Å–æ–º–Ω–µ–≤–∞—é—Å—å –Ω–∞—Å—á—ë—Ç –±—ã—Å—Ç—Ä–æ—Ç—ã. –ú–æ–∂–Ω–æ –±—ã –ø—Ä–æ—Ç–µ—Å—Ç–∏—Ä–æ–≤–∞—Ç—å - –Ω–æ –∞ –Ω–∞ —Ñ–∏–≥–∞? –ò –≤–æ–æ–±—â–µ - –Ω—É–∂–Ω–æ –ª–∏ –∏—Å–∫–∞—Ç—å –∏—Å—Ç–æ—á–Ω–∏–∫–∏, –≤ –∫–æ—Ç–æ—Ä—ã—Ö —Ä–µ—à–∞—é—Ç –∑–∞–¥–∞—á—É —É—Ä–æ–≤–Ω—è 2*2=4, –µ—Å–ª–∏ —ç—Ç–æ –Ω–µ –ø—Ä–æ—Å—Ç–æ, –∞ –æ—á–µ–Ω—å –ø—Ä–æ—Å—Ç–æ?
_________________
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
VladislavS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –°–± –æ–∫—Ç 22, 2022 22:19:19 |
|
| –°–æ–±—É—Ç—ã–ª—å–Ω–∏–∫ –ö–æ—Ç–∞ |
|
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 433
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –º–∞–π 01, 2018 19:44:47
–°–æ–æ–±—â–µ–Ω–∏–π: 2557
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ò–Ω—Ç–µ—Ä–µ—Å–Ω–æ –±—ã –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å —Å–≥–µ–Ω–µ—Ä–∏—Ä–æ–≤–∞–Ω–Ω—ã–π –∫–æ–¥ —Å –µ–Ω—Ç–æ–π —Å–∞–º–æ–π –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏—é -O3. –ù—É —Ç–∞–º –≤ —Å—Ç—Ä–æ–∫–µ –ø–∞—Ä–∞–º–µ—Ç—Ä–æ–≤ –ø–æ–º–µ–Ω—è–π—Ç–µ -Os –Ω–∞ -O3. –í —á—ë–º —Å–ª–æ–∂–Ω–æ—Å—Ç—å —Ç–æ? –Ø –Ω–µ –ø—Ä–µ–¥—Å—Ç–∞–≤–ª—è—é, –∫–∞–∫ –º–æ–∂–Ω–æ –∫–æ—Ä–æ—á–µ - —É –º–µ–Ω—è –Ω–∏ –æ–¥–Ω–æ–π –ª–∏—à–Ω–µ–π –æ–ø–µ—Ä–∞—Ü–∏–∏. –ù–µ, –∫–æ—Ä–æ—á–µ, –∞ –±—ã—Å—Ç—Ä–µ–µ! –ò —Ä–∞–∑—Ä–∞–±–æ—Ç—á–∏–∫–∏ –∫–æ–º–ø–∏–ª—è—Ç–æ—Ä–æ–≤ –∑–Ω–∞—é—Ç –∫–∞–∫ —ç—Ç–æ –¥–µ–ª–∞—Ç—å. –º–æ–∂–Ω–æ –ª–∏ –∑–∞—Å—Ç–∞–≤–∏—Ç—å –∫–æ–º–ø–∞–π–ª–µ—Ä —Ä–∞–∑–º–µ—â–∞—Ç—å –º–∞—Å—Å–∏–≤ –Ω–∞ –≥—Ä–∞–Ω–∏—Ü–µ –±–ª–æ–∫–∞. –ï—Å—Ç—å –∞—Ç—Ä–∏–±—É—Ç—ã –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è –¥–∞–Ω–Ω—ã—Ö. –ò–ª–∏, –º–æ–∂–µ—Ç –±—ã—Ç—å, –°–∏ - —è–∑—ã–∫ –Ω–∞—Å—Ç–æ–ª—å–∫–æ –≤—ã—Å–æ–∫–æ–≥–æ —É—Ä–æ–≤–Ω—è, —á—Ç–æ –≥–µ–Ω–µ—Ä–∏—Ä—É–µ—Ç —Å–µ–∫—Ä–µ—Ç–Ω—ã–µ —Å—É–ø–µ—Ä–±—ã—Å—Ç—Ä—ã–µ –∫–æ–º–∞–Ω–¥—ã, –Ω–µ–¥–æ—Å—Ç—É–ø–Ω—ã–µ –∞—Å—Å–µ–º–±–ª–µ—Ä—É ? –ö–æ–º–∞–Ω–¥—ã —Ç–æ —Ç–µ –∂–µ, –∞ –≤–æ—Ç –ø—Ä–∏–º–µ–Ω—è—Ç—å –∏—Ö –º–æ–∂–Ω–æ –ø–æ —Ä–∞–∑–Ω–æ–º—É. –ï—Å–ª–∏ —á–µ—Å—Ç–Ω–æ, —Ç–æ –∑–∞–∫–æ–Ω—á–µ–Ω–Ω–æ–≥–æ —Ä–∞–±–æ—á–µ–≥–æ –∫–æ–¥–∞ –º—ã –µ—â—ë –∏ –Ω–µ –≤–∏–¥–µ–ª–∏. –ü–æ—Ä–æ—á–∏—Ç—å –Ω–µ—á–µ–≥–æ. –ù–∞—Å—á—ë—Ç —Å—Å—ã–ª–æ–∫. –ü–µ—Ä–≤–∞—è - –∫–∞–∫–æ–µ –æ—Ç–Ω–æ—à–µ–Ω–∏–µ –∏–º–µ–µ—Ç –ú–µ–ª–∫–æ—Å–æ—Ñ—Ç –∫ –ê—Ç–º–µ–ª –∏ –ø–æ—á–µ–º—É –≤ –Ω—ë–º –¥–æ–ª–∂–Ω—ã –±—ã—Ç—å –∫–æ–¥—ã AVR? –î–µ–ª–æ –≤ —Ç–æ–º, —á—Ç–æ –∫–æ–¥ memcmp –≤ —Å—Ç–∞–Ω–¥–∞—Ä—Ç–Ω—ã—Ö –±–∏–±–ª–∏–æ—Ç–µ–∫–∞—Ö –¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ –Ω–∞–≤–æ—Ä–æ—á–µ–Ω–Ω—ã–π –¥–ª—è –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–∏ –Ω–∞ —Ä–∞–∑–Ω—ã—Ö –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–∞—Ö. –û–Ω —É—á–∏—Ç—ã–≤–∞–µ—Ç —Ä–∞–∑—Ä—è–¥–Ω–æ—Å—Ç—å, –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏–µ –¥–∞–Ω–Ω—ã—Ö –∏ "—Ç–∏–ø –∏–Ω–¥–µ–π—Ü–µ–≤". –ö–æ–¥ –æ—Ç –º–µ–ª–∫–æ–º—è–≥–∫–∏—Ö, –∫–∞–∫ –º–Ω–µ –∫–∞–∂–µ—Ç—Å—è, –Ω–µ–ø–ª–æ—Ö–æ –¥–ª—è –≤–æ—Å—å–º–∏–±–∏—Ç–æ–∫ –ø–æ–¥—Ö–æ–¥–∏—Ç –∏ –≤ —Å—Ç–∞–Ω–¥–∞—Ä—Ç–Ω–æ–π –±–∏–±–ª–∏–æ—Ç–µ–∫–µ avr gcc –æ–Ω –Ω–µ –¥–æ–ª–∂–µ–Ω –±—ã—Ç—å —Ö—É–∂–µ. –ü–æ –≤—Ç–æ—Ä–æ–π —Å—Å—ã–ª–∫–µ. –ù–∞ –º–æ–π –≤–∑–≥–ª—è–¥, –∫–æ–¥ –¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ –º—É—Ç–Ω—ã–π, –∏—Å–ø–æ–ª—å–∑—É–µ—Ç —Ç—É–µ–≤—É —Ö—É—á—É —Ä–µ–≥–∏—Å—Ç—Ä–æ–≤, –æ–±—ä—ë–º –±–æ–ª—å—à–µ –º–æ–µ–≥–æ –∏ —Å–æ–º–Ω–µ–≤–∞—é—Å—å –Ω–∞—Å—á—ë—Ç –±—ã—Å—Ç—Ä–æ—Ç—ã. –í–æ-–ø–µ—Ä–≤—ã—Ö, –Ω–µ –ø—É—Ç–∞–µ–º —Ä–∞–∑–º–µ—Ä –∏ —Å–∫–æ—Ä–æ—Å—Ç—å. –í–æ-–≤—Ç–æ—Ä—ã—Ö, —Ä–µ–≥–∏—Å—Ç—Ä—ã –Ω–∞ —Ç–æ –∏ –µ—Å—Ç—å, —á—Ç–æ–±—ã –∏—Ö –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å. –í-—Ç—Ä–µ—Ç—å–∏—Ö, —Å—Ä–∞–≤–Ω–∏–≤–∞—Ç—å —Å—Ç–æ–∏—Ç –Ω–µ —Ñ—Ä–∞–≥–º–µ–Ω—Ç –∫–æ–¥–∞, –∞ –∑–∞–∫–æ–Ω—á–µ–Ω–Ω–æ–µ —Ä–µ—à–µ–Ω–∏–µ. –í-—á–µ—Ç–≤—ë—Ä—Ç—ã—Ö, –ø–æ—Å—Ç–∞–≤—å—Ç–µ -O3, –µ—Å–ª–∏ –Ω—É–∂–Ω–∞ —Å–∫–æ—Ä–æ—Å—Ç—å. –ú–æ–∂–Ω–æ –±—ã –ø—Ä–æ—Ç–µ—Å—Ç–∏—Ä–æ–≤–∞—Ç—å - –Ω–æ –∞ –Ω–∞ —Ñ–∏–≥–∞? –ù—É –∫–æ–Ω–µ—á–Ω–æ, –º–æ–∂–Ω–æ –ø—Ä–æ—Å—Ç–æ –Ω–∞–∑–Ω–∞—á–∏—Ç—å —Å–µ–±—è –ø–æ–±–µ–¥–∏—Ç–µ–ª–µ–º. –ó–´: –ê –µ—Å—Ç—å –µ—â—ë –∫–æ–º–ø–∏–ª—è—Ç–æ—Ä –¥–ª—è AVR –æ—Ç IAR...
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
akl
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å –æ–∫—Ç 23, 2022 07:13:16 |
|
–ö–∞—Ä–º–∞: 66
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 1023
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü—Ç –º–∞—Ä 07, 2008 06:54:43
–°–æ–æ–±—â–µ–Ω–∏–π: 4381
–û—Ç–∫—É–¥–∞: –ò–∂–µ–≤—Å–∫
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 2
|
–ö–∞–∫ –≤–∞—Ä–∏–∞–Ω—Ç, –Ω–∞ –æ—Å–Ω–æ–≤–µ –≤—ã—à–µ –ø—Ä–µ–¥–ª–æ–∂–µ–Ω–Ω—ã—Ö —Ä–µ—à–µ–Ω–∏–π. 26 –±–∞–π—Ç –∫–æ–¥–∞ –∏ 364 —Ü–∏–∫–ª–∞ —Å—Ä–∞–≤–Ω–µ–Ω–∏—è –æ–¥–∏–Ω–∞–∫–æ–≤—ã—Ö –º–∞—Å—Å–∏–≤–æ–≤. –°–ø–æ–π–ª–µ—Ä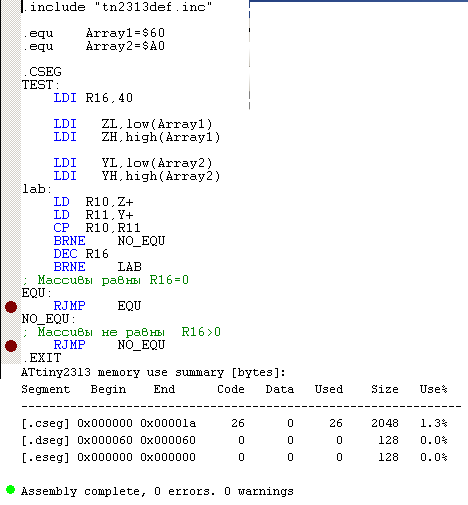
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
Dimon456
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å –æ–∫—Ç 23, 2022 09:18:24 |
|
–ö–∞—Ä–º–∞: 20
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 145
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Å –¥–µ–∫ 25, 2016 08:34:54
–°–æ–æ–±—â–µ–Ω–∏–π: 1849
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–•–≤–∞—Ç–∏—Ç—å —Å–ø–æ—Ä–∏—Ç—å –°–ø–æ–π–ª–µ—Ä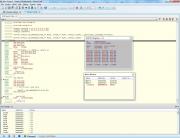 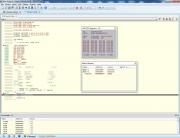
–ù–µ –∑–Ω–∞—é, –ø—Ä–∞–≤–∏–ª—å–Ω–æ asm-–≤—Å—Ç–∞–≤–∫—É —Å–¥–µ–ª–∞–ª, –Ω–µ –ø—Ä–∞–≤–∏–ª—å–Ω–æ, –Ω–µ –≤–∞–∂–Ω–æ. –Ý–µ–≥–∏—Å—Ç—Ä—ã r10 r11 –Ω–∞–¥–æ –∫–∞–∫-—Ç–æ –Ω–∞ –≤—ã–±–æ—Ä –∫–æ–º–ø–∏–ª—è—Ç–æ—Ä–∞ –ø—Ä–µ–¥–æ—Å—Ç–∞–≤–∏—Ç—å.
–ê —Ç–∞–∫ 141–º–∫—Å –ø—Ä–æ—Ç–∏–≤ 77–º–∫—Å –Ω–∞ —Ç–∞–∫—Ç–æ–≤–æ–π —á–∞—Å—Ç–æ—Ç–µ –ú–ö 1–ú–ì—Ü, —Ç–∞–∫—Ç—ã —Å–∞–º–∏ –ø–æ—Å—á–∏—Ç–∞–µ—Ç–µ.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
Jack_A
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å –æ–∫—Ç 23, 2022 10:33:33 |
|
| –î—Ä—É–≥ –ö–æ—Ç–∞ |
|
–ö–∞—Ä–º–∞: 62
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 889
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–ø—Ä 24, 2007 07:45:40
–°–æ–æ–±—â–µ–Ω–∏–π: 6238
–û—Ç–∫—É–¥–∞: Minsk
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ï—Å–ª–∏ —á–µ—Å—Ç–Ω–æ, —Ç–æ –∑–∞–∫–æ–Ω—á–µ–Ω–Ω–æ–≥–æ —Ä–∞–±–æ—á–µ–≥–æ –∫–æ–¥–∞ –º—ã –µ—â—ë –∏ –Ω–µ –≤–∏–¥–µ–ª–∏. –ü–æ—Ä–æ—á–∏—Ç—å –Ω–µ—á–µ–≥–æ. –ù–∞–≤–µ—Ä–Ω–æ–µ, –Ω–µ—á–µ—Å—Ç–Ω–æ. –ü–æ—Ç–æ–º—É —á—Ç–æ –º–æ–π –∫–æ–¥ –≤ –ø–æ—Å—Ç–µ –æ—Ç 22.10 6.06pm –í–æ–æ–±—â–µ –º–Ω–µ —Å—Ç–∞–ª –Ω–µ–∏–Ω—Ç–µ—Ä–µ—Å–µ–Ω —ç—Ç–æ—Ç –ø—É—Å—Ç–æ–π —Å–ø–æ—Ä –æ–± –æ—á–µ–≤–∏–¥–Ω—ã—Ö –≤–µ—â–∞—Ö.
_________________
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
VNS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ö–∞–∫ –∑–∞–ø–∏—Å–∞—Ç—å –∫–æ–¥ –ª–∞–∫–æ–Ω–∏—á–Ω–µ–µ –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å –æ–∫—Ç 23, 2022 14:19:05 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
|
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 236
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –ü—Ç –¥–µ–∫ 10, 2021 12:48:46
–°–æ–æ–±—â–µ–Ω–∏–π: 1563
–û—Ç–∫—É–¥–∞: –¢—é–º–µ–Ω—å
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
26 –±–∞–π—Ç –∫–æ–¥–∞ –∏ 364 —Ü–∏–∫–ª–∞  –ú–æ–π –≤–∞—Ä–∏–∞–Ω—Ç: –í–ª–æ–∂–µ–Ω–∏–µ:
1.png [5.9 KiB]
–°–∫–∞—á–∏–≤–∞–Ω–∏–π: 64
38 слов – 291 цикл… на выполнение алгоритма при 1 МГц уходит 410 мкс…
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 2 –∏–∑ 4
|
[ –°–æ–æ–±—â–µ–Ω–∏–π: 71 ] |
, , , |
–ö—Ç–æ —Å–µ–π—á–∞—Å –Ω–∞ —Ñ–æ—Ä—É–º–µ |
–°–µ–π—á–∞—Å —ç—Ç–æ—Ç —Ñ–æ—Ä—É–º –ø—Ä–æ—Å–º–∞—Ç—Ä–∏–≤–∞—é—Ç: –Ω–µ—Ç –∑–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω–Ω—ã—Ö –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π –∏ –≥–æ—Å—Ç–∏: 13 |
|
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –Ω–∞—á–∏–Ω–∞—Ç—å —Ç–µ–º—ã
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –æ—Ç–≤–µ—á–∞—Ç—å –Ω–∞ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —É–¥–∞–ª—è—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –¥–æ–±–∞–≤–ª—è—Ç—å –≤–ª–æ–∂–µ–Ω–∏—è
|
|
|









