Как записать код лаконичнее

Re: Как записать код лаконичнее
Кстати, еще один способ - в цикле от 0 до n проводить накопление абсолютной (без учета знака) разности элементов массивов: x += abs(A[n] - B[n]). В конце цикла проверить значение x. Если оно отличается от 0, значит массивы разные по значениям.
- Реклама
-
veso74
- Поставщик валерьянки для Кота
- Сообщения: 1909
- Зарегистрирован: Сб май 05, 2012 20:24:52
- Откуда: KN34PC, Болгария
- Контактная информация:
Re: Как записать код лаконичнее
Если собираемся применять математику, существует столько методов, сколько хотим. Напр. CRC даже в датчики вложены. Но вычислительная мощность крошечных mcu идет на "безжалостное" использование. С любовью напр. возвращаюсь к использованию, напр. к люб. ATtiny13 - сколько функций и математики можно собрать, а объем памяти все равно не достигнет  .
.
- Реклама

-
Eddy_Em

- Собутыльник Кота
- Сообщения: 2516
- Зарегистрирован: Пт июл 12, 2019 22:52:01
- Контактная информация:
Re: Как записать код лаконичнее
[uquote="MLX90640",url="/forum/viewtopic.php?p=4307866#p4307866"]Прикольно! Я тоже хачю так песать!  [/uquote]
[/uquote]
Самое убогое, что я видел - инициализация абдуринщиками ЖК-экранчика. Когда нужно толпу команд инициализации переслать, периодически небольшие паузы делать. И китаезы, как обычно, ничего, лучше тупого копипаста на несколько страниц текста, не придумали. Хотя достаточно завести структуру, инициализировать во флеше, а потом в цикле все это УГ пересылать, делая при необходимости нужные паузы…
Самое убогое, что я видел - инициализация абдуринщиками ЖК-экранчика. Когда нужно толпу команд инициализации переслать, периодически небольшие паузы делать. И китаезы, как обычно, ничего, лучше тупого копипаста на несколько страниц текста, не придумали. Хотя достаточно завести структуру, инициализировать во флеше, а потом в цикле все это УГ пересылать, делая при необходимости нужные паузы…
Re: Как записать код лаконичнее
Ой, да ладно, дядя! Ардуино - это С++, ты зто хаваешь? Или просто, какой я тут крутой?
- Реклама

Re: Как записать код лаконичнее
[uquote="MLX90640",url="/forum/viewtopic.php?p=4307920#p4307920"]Кстати, еще один способ - в цикле от 0 до n проводить накопление абсолютной (без учета знака) разности элементов массивов: x += abs(A[n] - B[n]). В конце цикла проверить значение x. Если оно отличается от 0, значит массивы разные по значениям.[/uquote]
Во-первых, функция "abs" не бесплатная и имеет схожие затраты, как и у "if". Что, вообще, лишает смысла.
Во-вторых, на двух абсолютно разных массивах вы можете получить "0". Ошибку сами найдете?
Во-первых, функция "abs" не бесплатная и имеет схожие затраты, как и у "if". Что, вообще, лишает смысла.
Во-вторых, на двух абсолютно разных массивах вы можете получить "0". Ошибку сами найдете?
- Реклама
-
VNS

- Говорящий с текстолитом
- Сообщения: 1627
- Зарегистрирован: Пт дек 10, 2021 12:48:46
- Откуда: Тюмень
Re: Как записать код лаконичнее
[uquote="главный колбасист",url="/forum/viewtopic.php?p=4307852#p4307852"]А как ?[/uquote]
Один из способов такой...
Один из способов такой...
- Реклама

Re: Как записать код лаконичнее
[uquote="u37",url="/forum/viewtopic.php?p=4308054#p4308054"]Во-первых, функция "abs" не бесплатная и имеет схожие затраты,[/uquote]
Во-первых, знаете, как выражается разность в формате unsigned? Математику надо хоть немного то знать
[uquote="u37",url="/forum/viewtopic.php?p=4308054#p4308054"]Во-вторых, на двух абсолютно разных массивах вы можете получить "0". Ошибку сами найдете?[/uquote]
Во-вторых, яж написал - разность по модулю, без учета знака то есть. Накопление этой разности. Если хотябы один элемент отличается в массивах, то разность уже не будет нулевой. а если второй элемент отличается в другую сторону, то разность по модулю не будет отрицательной и накопление разности не обнулится.
Во-первых, знаете, как выражается разность в формате unsigned?
[uquote="u37",url="/forum/viewtopic.php?p=4308054#p4308054"]Во-вторых, на двух абсолютно разных массивах вы можете получить "0". Ошибку сами найдете?[/uquote]
Во-вторых, яж написал - разность по модулю, без учета знака то есть. Накопление этой разности. Если хотябы один элемент отличается в массивах, то разность уже не будет нулевой. а если второй элемент отличается в другую сторону, то разность по модулю не будет отрицательной и накопление разности не обнулится.
Последний раз редактировалось MLX90640 Сб окт 22, 2022 07:57:59, всего редактировалось 1 раз.
Re: Как записать код лаконичнее
... ошибки MLX90640 искать не собирается, а свой возраст продемонстрирован очень четко. На сём разговор закончен.
Re: Как записать код лаконичнее
u37,
Я там пояснил для вас, даже как для школьника, суть модуля разности - это просто расстояние между двумя точками без учета направления. Эта разность всегда положительна. Так что ищите ошибки в своей математике за 5 класс
Вот что за манера на этом форуме - чуть чо, не разобравшись в вопросе, сразу обвинять в ошибках и упорно не желать разобраться в сути. Недавно этот, как его там, Demiurg, с пеной у рта доказывал, как надо функции писать, и тоже ссылался на возраст. А теперь вот и u37 доказывает свои незнания школьной математики за 5 класс
Ну и по аналогии с Demiurg-ом, давайте разберем, что вы, u37 тут понаписали:
Если делаете логическим сравнением по xor, то незачем делить массив на группы по 4 штуки. Сей глубокий смысел излишен. Сделайте просто xor по одному элементу из каждого массива и не мудрите.
Я там пояснил для вас, даже как для школьника, суть модуля разности - это просто расстояние между двумя точками без учета направления. Эта разность всегда положительна. Так что ищите ошибки в своей математике за 5 класс
Вот что за манера на этом форуме - чуть чо, не разобравшись в вопросе, сразу обвинять в ошибках и упорно не желать разобраться в сути. Недавно этот, как его там, Demiurg, с пеной у рта доказывал, как надо функции писать, и тоже ссылался на возраст. А теперь вот и u37 доказывает свои незнания школьной математики за 5 класс
Ну и по аналогии с Demiurg-ом, давайте разберем, что вы, u37 тут понаписали:
Вас ист дас, что есть это? Поясните ход ваших мыслей. Зачем +4, почему i+3, что такое | и для чего оное? И зачем делите элементы массива по 4 штуки? А если массивы не кратные числу 4? А может сразу в одну линейку 40 штук записать? Или все-таки по одному?Код: Выделить всё
int cmp=0; for (.... +4) { cmp |=(r1[i] ^ r2[i]) | (r1[i+1] ^ r2[i+1]) | (r1[i+2] ^ r2[i+2]) | (r1[i+3] ^ r2[i+3]); } if (cmp == 0) ...
Если делаете логическим сравнением по xor, то незачем делить массив на группы по 4 штуки. Сей глубокий смысел излишен. Сделайте просто xor по одному элементу из каждого массива и не мудрите.
-
VNS
- Говорящий с текстолитом
- Сообщения: 1627
- Зарегистрирован: Пт дек 10, 2021 12:48:46
- Откуда: Тюмень
Re: Как записать код лаконичнее
MLX90640
Вам бы "семикласснику", манерам общения стоило бы поучиться… или Вы с пелёнок кипятком писаете? Свои ранее плюсы убрал, так как видимо не на пользу пошли…
или Вы с пелёнок кипятком писаете? Свои ранее плюсы убрал, так как видимо не на пользу пошли…  бревна в своём глазу не замечаете? Вопрос риторический, если что… базар разводить не буду...
бревна в своём глазу не замечаете? Вопрос риторический, если что… базар разводить не буду...
Вам бы "семикласснику", манерам общения стоило бы поучиться…

Re: Как записать код лаконичнее
[uquote="MLX90640",url="/forum/viewtopic.php?p=4308113#p4308113"]расстояние между двумя точками без учета направления. Эта разность всегда положительна.[/uquote]
Чисто математически - да. Но при реализации на МК... Досчитали до 256 - и плучили 0. Для разности мало одного байта? Берём минимум 2 ? Тогда: расширение первого байта-операнда до целого слова, потом второго, потом разность. Это отнюдь не 1 машинная команда в цикле.
В общем, пока конкурента моей реализации не вижу. И чего это многие как чёрт ладана боятся асма, хотя бы на уровне вставки? "У меня памяти достаточно, на френ мне ваш асм. Но вот почему оно так медленно работает?!"
Чисто математически - да. Но при реализации на МК... Досчитали до 256 - и плучили 0. Для разности мало одного байта? Берём минимум 2 ? Тогда: расширение первого байта-операнда до целого слова, потом второго, потом разность. Это отнюдь не 1 машинная команда в цикле.
В общем, пока конкурента моей реализации не вижу. И чего это многие как чёрт ладана боятся асма, хотя бы на уровне вставки? "У меня памяти достаточно, на френ мне ваш асм. Но вот почему оно так медленно работает?!"
Последний раз редактировалось Jack_A Сб окт 22, 2022 18:07:40, всего редактировалось 1 раз.

-
VladislavS

- Собутыльник Кота
- Сообщения: 2562
- Зарегистрирован: Вт май 01, 2018 19:44:47
Re: Как записать код лаконичнее
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308189#p4308189"]И чего это многие как чёрт ладана боятся асма, хотя бы на уровне вставки?[/uquote]Пока ЯВУ справляется с задачей, асм зло. Аргументы всё те же и уже десятки лет не меняются: трудоёмкость и совместимость.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308189#p4308189"]"У меня памети достаточно, на френ мне ваш асм. Но вот почему оно так медленно работает?!"[/uquote]Вот когда будет медленно работать, тогда и стоит найти узкое место и оптимизировать именно его. Тыкать асм куда ни попадя плохая идея.
Добавлено after 2 minutes 39 seconds:
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308189#p4308189"]В общем, пока конкурента моей реализации не вижу.[/uquote]Где можно посмотреть вашу реализацию?
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308189#p4308189"]"У меня памети достаточно, на френ мне ваш асм. Но вот почему оно так медленно работает?!"[/uquote]Вот когда будет медленно работать, тогда и стоит найти узкое место и оптимизировать именно его. Тыкать асм куда ни попадя плохая идея.
Добавлено after 2 minutes 39 seconds:
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308189#p4308189"]В общем, пока конкурента моей реализации не вижу.[/uquote]Где можно посмотреть вашу реализацию?
Re: Как записать код лаконичнее
[uquote="VladislavS",url="/forum/viewtopic.php?p=4308216#p4308216"]Где можно посмотреть вашу реализацию?[/uquote]
Дык у меня оно - на уровне идеи (пост от 21.10)
(пост от 21.10)
А так приблизительно выглядело бы:
Если бы массивы были в одном 256-байтовом сегменте, было бы ещё проще - не проверяли бы ZH, но компилевич нам это не гарантирует.
Полностью согласен - асм пихать куда ни попадя - плохая идея, при этом - не моя Но если надо, то...
И непонятна хотелка ТС насчёт "лаконичности" - в МК не лезет? быстродействия не хватает? или места на диске компа в директории MY_PROJECTS ?
-----------------------
ПыСы Давно не писал на асме, там, кажется в LDI на 2 умножать надо
Дык у меня оно - на уровне идеи
А так приблизительно выглядело бы:
Код: Выделить всё
LDI ZL,low(Array1)
LDI ZH,highArray1)
LDI YL,low(Array2)
LDI YH,high(Array2)
lab: ld R16,z+
ld R1,y+
sub R16.R1
brne out_cycle
cpi ZH,high(Array1+40)
brlo lab
cpi ZL,low(Array1+40)
brlo lab
out_cycle: tst R16 ; вот сюда мы придём с 0 в R16 , если массивы совпали :))
Полностью согласен - асм пихать куда ни попадя - плохая идея, при этом - не моя
И непонятна хотелка ТС насчёт "лаконичности" - в МК не лезет? быстродействия не хватает? или места на диске компа в директории MY_PROJECTS ?
-----------------------
ПыСы Давно не писал на асме, там, кажется в LDI на 2 умножать надо
-
VladislavS
- Собутыльник Кота
- Сообщения: 2562
- Зарегистрирован: Вт май 01, 2018 19:44:47
Re: Как записать код лаконичнее
Ну, давайте посмотрим. Достаточно несложно ищется код memcmp из Microsoft CRT, который слегка избыточен под задачу ТС. Или напишем прямо в лоб сами. Ничем не хуже и гарантировано работает, да ещё на любом компиляторе и процессоре. А если оптимизацию -O3 поставить, то ещё и быстрее вашего варианта. Так что, победу вы себе рановато приписали.
Re: Как записать код лаконичнее
Интересно бы посмотреть сгенерированный код с ентой самой оптимизацию -O3. Я не представляю, как можно короче - у меня ни одной лишней операции. Как я уже выразился, быстрее можно только если оба массива находятся в одной "странице" памяти (можно - каждый в своей), тогда не нужно проверять ZH на конец цикла. Я для МК на Си не писа'л никогда, поэтому не знаю - можно ли заставить компайлер размещать массив на границе блока.
Или, может быть, Си - язык настолько высокого уровня, что генерирует секретные супербыстрые команды, недоступные ассемблеру ?
А то получается - мой рекорд пытаются опорочить бездоказательным "может быть..."
---------------------------
Насчёт ссылок. Первая - какое отношение имеет Мелкософт к Атмел и почему в нём должны быть коды AVR? Может, где-то в нём что-то и глубоко упрятано по этой теме, но ввиду позднего в ремени и оно_мне_надо? искать не стал. По второй ссылке. На мой взгляд, код достаточно мутный, использует туеву хучу регистров, объём больше моего и сомневаюсь насчёт быстроты. Можно бы протестировать - но а на фига?
И вообще - нужно ли искать источники, в которых решают задачу уровня 2*2=4, если это не просто, а очень просто?
Или, может быть, Си - язык настолько высокого уровня, что генерирует секретные супербыстрые команды, недоступные ассемблеру ?
А то получается - мой рекорд пытаются опорочить бездоказательным "может быть..."
---------------------------
Насчёт ссылок. Первая - какое отношение имеет Мелкософт к Атмел и почему в нём должны быть коды AVR? Может, где-то в нём что-то и глубоко упрятано по этой теме, но ввиду позднего в ремени и оно_мне_надо? искать не стал. По второй ссылке. На мой взгляд, код достаточно мутный, использует туеву хучу регистров, объём больше моего и сомневаюсь насчёт быстроты. Можно бы протестировать - но а на фига?
И вообще - нужно ли искать источники, в которых решают задачу уровня 2*2=4, если это не просто, а очень просто?
-
VladislavS
- Собутыльник Кота
- Сообщения: 2562
- Зарегистрирован: Вт май 01, 2018 19:44:47
Re: Как записать код лаконичнее
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Интересно бы посмотреть сгенерированный код с ентой самой оптимизацию -O3.[/uquote]Ну там в строке параметров поменяйте -Os на -O3. В чём сложность то?
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Я не представляю, как можно короче - у меня ни одной лишней операции.[/uquote]Не, короче, а быстрее! И разработчики компиляторов знают как это делать.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]можно ли заставить компайлер размещать массив на границе блока.[/uquote]Есть атрибуты выравнивания данных.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Или, может быть, Си - язык настолько высокого уровня, что генерирует секретные супербыстрые команды, недоступные ассемблеру ?[/uquote]Команды то те же, а вот применять их можно по разному.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]А то получается - мой рекорд пытаются опорочить бездоказательным "может быть..." [/uquote]Если честно, то законченного рабочего кода мы ещё и не видели. Порочить нечего.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Насчёт ссылок. Первая - какое отношение имеет Мелкософт к Атмел и почему в нём должны быть коды AVR?[/uquote]Дело в том, что код memcmp в стандартных библиотеках достаточно навороченный для оптимизации на разных процессорах. Он учитывает разрядность, выравнивание данных и "тип индейцев". Код от мелкомягких, как мне кажется, неплохо для восьмибиток подходит и в стандартной библиотеке avr gcc он не должен быть хуже.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]По второй ссылке. На мой взгляд, код достаточно мутный, использует туеву хучу регистров, объём больше моего и сомневаюсь насчёт быстроты.[/uquote]Во-первых, не путаем размер и скорость. Во-вторых, регистры на то и есть, чтобы их использовать. В-третьих, сравнивать стоит не фрагмент кода, а законченное решение. В-четвёртых, поставьте -O3, если нужна скорость.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Можно бы протестировать - но а на фига?[/uquote]Ну конечно, можно просто назначить себя победителем.
ЗЫ: А есть ещё компилятор для AVR от IAR...
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Я не представляю, как можно короче - у меня ни одной лишней операции.[/uquote]Не, короче, а быстрее! И разработчики компиляторов знают как это делать.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]можно ли заставить компайлер размещать массив на границе блока.[/uquote]Есть атрибуты выравнивания данных.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Или, может быть, Си - язык настолько высокого уровня, что генерирует секретные супербыстрые команды, недоступные ассемблеру ?
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]А то получается - мой рекорд пытаются опорочить бездоказательным "может быть..."
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Насчёт ссылок. Первая - какое отношение имеет Мелкософт к Атмел и почему в нём должны быть коды AVR?[/uquote]Дело в том, что код memcmp в стандартных библиотеках достаточно навороченный для оптимизации на разных процессорах. Он учитывает разрядность, выравнивание данных и "тип индейцев". Код от мелкомягких, как мне кажется, неплохо для восьмибиток подходит и в стандартной библиотеке avr gcc он не должен быть хуже.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]По второй ссылке. На мой взгляд, код достаточно мутный, использует туеву хучу регистров, объём больше моего и сомневаюсь насчёт быстроты.[/uquote]Во-первых, не путаем размер и скорость. Во-вторых, регистры на то и есть, чтобы их использовать. В-третьих, сравнивать стоит не фрагмент кода, а законченное решение. В-четвёртых, поставьте -O3, если нужна скорость.
[uquote="Jack_A",url="/forum/viewtopic.php?p=4308537#p4308537"]Можно бы протестировать - но а на фига?[/uquote]Ну конечно, можно просто назначить себя победителем.
ЗЫ: А есть ещё компилятор для AVR от IAR...
Re: Как записать код лаконичнее
Как вариант, на основе выше предложенных решений. 26 байт кода и 364 цикла сравнения одинаковых массивов.
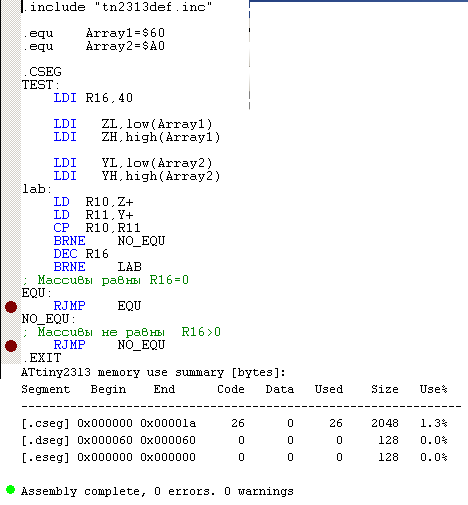
Спойлер
- Вложения
-
- Сравнение массивов.PNG
- (14.96 КБ) 132 скачивания
Re: Как записать код лаконичнее
Хватить спорить
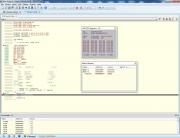
Не знаю, правильно asm-вставку сделал, не правильно, не важно. Регистры r10 r11 надо как-то на выбор компилятора предоставить.
А так 141мкс против 77мкс на тактовой частоте МК 1МГц, такты сами посчитаете.
Спойлер


Не знаю, правильно asm-вставку сделал, не правильно, не важно. Регистры r10 r11 надо как-то на выбор компилятора предоставить.
А так 141мкс против 77мкс на тактовой частоте МК 1МГц, такты сами посчитаете.
Re: Как записать код лаконичнее
[uquote="VladislavS",url="/forum/viewtopic.php?p=4308558#p4308558"]Если честно, то законченного рабочего кода мы ещё и не видели. Порочить нечего.[/uquote]
Наверное, нечестно. Потому что мой код в посте от 22.10 6.06pm
Вообще мне стал неинтересен этот пустой спор об очевидных вещах.
Наверное, нечестно. Потому что мой код в посте от 22.10 6.06pm
Вообще мне стал неинтересен этот пустой спор об очевидных вещах.
-
VNS
- Говорящий с текстолитом
- Сообщения: 1627
- Зарегистрирован: Пт дек 10, 2021 12:48:46
- Откуда: Тюмень
Re: Как записать код лаконичнее
[uquote="akl",url="/forum/viewtopic.php?p=4308639#p4308639"]26 байт кода и 364 цикла[/uquote]

Мой вариант: 38 слов – 291 цикл… на выполнение алгоритма при 1 МГц уходит 410 мкс…
Мой вариант: 38 слов – 291 цикл… на выполнение алгоритма при 1 МГц уходит 410 мкс…