Описание моих экспериментов по созданию простого фонемного синтезатора речи на микроконтроллере.
Было желание оформить в виде статьи на сайт, но так и не осилил Кото-редактор. Поэтому кладу здесь в PDF.
Надеюсь, что кому-то окажется полезным.
Схемы, платы, исходники с прошивками лежат на Яндекс Диске:
http://yadi.sk/d/H-2kJlg39XgwW
Синтез речи на STM32F100
-
uk8amk
- Поставщик валерьянки для Кота
- Сообщения: 2222
- Зарегистрирован: Вт ноя 27, 2007 11:32:06
- Откуда: Tashkent
Синтез речи на STM32F100
- Вложения
-
- sintez_text.pdf
- Описание синтезатора речи
- (162.92 КБ) 2122 скачивания
- Реклама
-
oleg110592

- Друг Кота
- Сообщения: 3832
- Зарегистрирован: Сб сен 10, 2011 17:46:25
Re: Синтез речи на STM32F100
спасибо - очень интересно
- Реклама

-
uk8amk
- Поставщик валерьянки для Кота
- Сообщения: 2222
- Зарегистрирован: Вт ноя 27, 2007 11:32:06
- Откуда: Tashkent
Re: Синтез речи на STM32F100
Там среди файлов есть образец записи в MP3. Хотелось бы узнать ваши мнения, насколько понятно оно разговаривает. Сам я уже прислушался и не могу дать объективную оценку результата.
-
uk8amk
- Поставщик валерьянки для Кота
- Сообщения: 2222
- Зарегистрирован: Вт ноя 27, 2007 11:32:06
- Откуда: Tashkent
Re: Синтез речи на STM32F100
Кстати это не единственно возможный вариант синтезатора.
Недавно мне попадались простые TTS на AVR 8-бит микроконтроллерах:
- Atmega8
http://bascom.at.ua/publ/sintezator_rec ... a/1-1-0-79
- Atmega32
http://roboforum.ru/forum2/topic5106.html
Недавно мне попадались простые TTS на AVR 8-бит микроконтроллерах:
- Atmega8
http://bascom.at.ua/publ/sintezator_rec ... a/1-1-0-79
- Atmega32
http://roboforum.ru/forum2/topic5106.html
- Реклама

-
urry

- Сверлит текстолит когтями
- Сообщения: 1262
- Зарегистрирован: Пн дек 08, 2008 10:58:48
- Откуда: Винница
- Контактная информация:
Re: Синтез речи на STM32F100
имхо, хотелось бы получше.
Кстати, а почему Вы не использовали в качестве внешней памяти ммс сд карточку ?
Тогда размер библиотеки фонем можно было бы расширить.
Красиво, конечно, но практическое применение вряд ли найдет - говорилка с готовыми фразами уже есть...
Ну имхо.
Кстати, а почему Вы не использовали в качестве внешней памяти ммс сд карточку ?
Тогда размер библиотеки фонем можно было бы расширить.
Красиво, конечно, но практическое применение вряд ли найдет - говорилка с готовыми фразами уже есть...
Ну имхо.
- Реклама
-
oleg110592
- Друг Кота
- Сообщения: 3832
- Зарегистрирован: Сб сен 10, 2011 17:46:25
Re: Синтез речи на STM32F100
пару слов не совсем разборчиво, а так вполне, имхо бы приятнее был бы женский голос (иногда когда глаза устают слушаю книжки на планшете - синтезированный голос Алена вполне неплох). Насчет карточки - наверное можно было бы разместить все нужные живые фразы на ней, если конечно не читалка текста.uk8amk писал(а): Хотелось бы узнать ваши мнения, насколько понятно оно разговаривает...
- Реклама

-
uk8amk
- Поставщик валерьянки для Кота
- Сообщения: 2222
- Зарегистрирован: Вт ноя 27, 2007 11:32:06
- Откуда: Tashkent
Re: Синтез речи на STM32F100
Да, вы правы насчёт применения.
Для меня эта тема сейчас представляет чисто спортивный интерес.
Про MMC - это отдельный разговор. Может я не умею их готовить, но было несколько случаев полного зависания карточек(до резета питания). Из чего я делаю вывод о их невысокой надёжности в режиме SPI.
Для увеличения базы думаю заюзать M25P128 на 16 мегабайт или NAND flash от Samsung-a как недорогой вариант. Но NAND мне не очень нравится т.к. у него параллельная шина. А для быстрого прозрачного обмена нужен FSMC, что есть в камнях от LQFP100 и выше.
По голосам. Алёна вроде коммерческая. Нашёл и скачал только Ольгу. Но она без нарезки по аллофонам. А вручную проставлять маркеры - пару месяцев работы.
Имеется мужской голос с разметкой от TTS Festival(имя диктора не знаю). Но там тоже свои заморочки. Диктор всё равно читает с интонацией. У меня же система, как сейчас есть, не учитывает просодические характеристики. Вобщем есть над чем голову поломать.
Для меня эта тема сейчас представляет чисто спортивный интерес.
Про MMC - это отдельный разговор. Может я не умею их готовить, но было несколько случаев полного зависания карточек(до резета питания). Из чего я делаю вывод о их невысокой надёжности в режиме SPI.
Для увеличения базы думаю заюзать M25P128 на 16 мегабайт или NAND flash от Samsung-a как недорогой вариант. Но NAND мне не очень нравится т.к. у него параллельная шина. А для быстрого прозрачного обмена нужен FSMC, что есть в камнях от LQFP100 и выше.
По голосам. Алёна вроде коммерческая. Нашёл и скачал только Ольгу. Но она без нарезки по аллофонам. А вручную проставлять маркеры - пару месяцев работы.
Имеется мужской голос с разметкой от TTS Festival(имя диктора не знаю). Но там тоже свои заморочки. Диктор всё равно читает с интонацией. У меня же система, как сейчас есть, не учитывает просодические характеристики. Вобщем есть над чем голову поломать.
-
balmer

- Это не хвост, это антенна
- Сообщения: 1433
- Зарегистрирован: Вс дек 02, 2012 03:13:48
- Откуда: Калининград
Re: Синтез речи на STM32F100
Лично мне не нравятся щелчки между слогами. Но к сожалению не знаю - это исходное свойство звуков из которых синтезируется или микшере получается?uk8amk писал(а):Сам я уже прислушался и не могу дать объективную оценку результата.
-
oleg110592
- Друг Кота
- Сообщения: 3832
- Зарегистрирован: Сб сен 10, 2011 17:46:25
Re: Синтез речи на STM32F100
Алена тут вроде есть http://rsload.net/soft/document/8298-balabolka.html
применить можно - давно меня один заказчик мордует сделать бытовой термометр + влажность с голосом (только денег вкладывать не хочет), да еще можно напридумывать - например выключатель света с голосом и т.д., лишь бы внятно было.
з.ы. вроде по теме японский вокалоид по русски: http://www.youtube.com/watch?v=XhQUJgRGRdQ
применить можно - давно меня один заказчик мордует сделать бытовой термометр + влажность с голосом (только денег вкладывать не хочет), да еще можно напридумывать - например выключатель света с голосом и т.д., лишь бы внятно было.
з.ы. вроде по теме японский вокалоид по русски: http://www.youtube.com/watch?v=XhQUJgRGRdQ
-
uk8amk
- Поставщик валерьянки для Кота
- Сообщения: 2222
- Зарегистрирован: Вт ноя 27, 2007 11:32:06
- Откуда: Tashkent
Re: Синтез речи на STM32F100
Спасибо за отзывы.
Да, забыл сказать. Запись оразца MP3 с дешёвого микрофона, поэтому звук более жесткий. Но наверное вы уже и так догадались.
Излом тона в словах проходит по границам звуков из фонемной базы(там элементы различной длины - аллофоны, дифоны и трифоны). Я прочитал в одной советской книжке, что для более или менее сносного синтеза русского языка необходимо иметь как минимум 10000 разных аллофонов. Дело в том, что в непрерывной речи звуки перетекают плавно один в другой. И если база недостаточно большая, то не получится состыковать звуки без разрыва формант. Сейчас у меня 680 элементов и такие разрывы неизбежны. Вот как раз хорошо видно на сонограмме.

Во "взрослых" системах синтеза используются алгоритмы для сглаживания разрывов. У меня же сейчас вопроизводится как есть, без какой-либо дополнительной обработки. Ну и с учётом небольших вычислительных возможностей я могу максимум осилить плавную склейку звуков внахлёст(с плавным наездом-выездом). Надо будет как-нибудь попробовать этот вариант.
Про простые девайсы вроде термометра. В плане качества действительно будет лучше записать десяток отдельных слов, затем из них компилировать фразы. Как например это сделано здесь
http://radiokot.ru/circuit/digital/home/118/
А если применить сжатие звука и контроллер с достаточно большим объёмом памяти(256 и более КБ), то вполне может получиться одночиповое решение. А про заказчиков - правда. Пошёл сейчас народ либо бедный, либо жадный. Чем лечить такое - не знаю:)
Вчера попался еще один интересный вариант простенького синтезатора на PIC16F628 из журнала Everyday Practical Electronics. Статья во вложении.
Да, забыл сказать. Запись оразца MP3 с дешёвого микрофона, поэтому звук более жесткий. Но наверное вы уже и так догадались.
Излом тона в словах проходит по границам звуков из фонемной базы(там элементы различной длины - аллофоны, дифоны и трифоны). Я прочитал в одной советской книжке, что для более или менее сносного синтеза русского языка необходимо иметь как минимум 10000 разных аллофонов. Дело в том, что в непрерывной речи звуки перетекают плавно один в другой. И если база недостаточно большая, то не получится состыковать звуки без разрыва формант. Сейчас у меня 680 элементов и такие разрывы неизбежны. Вот как раз хорошо видно на сонограмме.
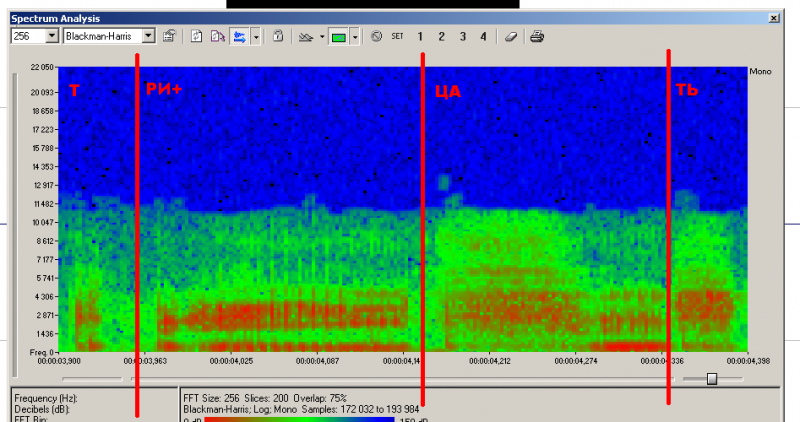
Во "взрослых" системах синтеза используются алгоритмы для сглаживания разрывов. У меня же сейчас вопроизводится как есть, без какой-либо дополнительной обработки. Ну и с учётом небольших вычислительных возможностей я могу максимум осилить плавную склейку звуков внахлёст(с плавным наездом-выездом). Надо будет как-нибудь попробовать этот вариант.
Про простые девайсы вроде термометра. В плане качества действительно будет лучше записать десяток отдельных слов, затем из них компилировать фразы. Как например это сделано здесь
http://radiokot.ru/circuit/digital/home/118/
А если применить сжатие звука и контроллер с достаточно большим объёмом памяти(256 и более КБ), то вполне может получиться одночиповое решение. А про заказчиков - правда. Пошёл сейчас народ либо бедный, либо жадный. Чем лечить такое - не знаю:)
Вчера попался еще один интересный вариант простенького синтезатора на PIC16F628 из журнала Everyday Practical Electronics. Статья во вложении.
- Вложения
-
- 284_N58.djvu
- PIC Speech Synthesiser. EPE-2007
- (176.92 КБ) 368 скачиваний
-
uk8amk
- Поставщик валерьянки для Кота
- Сообщения: 2222
- Зарегистрирован: Вт ноя 27, 2007 11:32:06
- Откуда: Tashkent
Re: Синтез речи на STM32F100
Завёл речевой декодер SPEEX на отладочной плате STM32 VLDiscovery.
Он относится к категории CELP и обеспечивает хороший коэффициент сжатия (скорость потока 1-2 килобайта в сек).
За основу были взяты материалы:
1.Статья с Easyelectronics
http://we.easyelectronics.ru/STM32/vosp ... speex.html
2.AN2812 Vocoder demonstration using a Speex audio codec
on STM32F101xx and STM32F103xx microcontrollers -- порт узкополосного варианта(8КГц) на STM32.
3.AN0055 - Application Note. Speex Codec. Порт кодека под контроллеры EFM32 от Energy micro. К сожалению исходники комплектуются только скомпилированной либой и толку от них ноль целых хрен десятых. Зато есть утилита speexenc, конвертирующая звуковые WAV-чики в h-файлы. Которые потом легко цепляются компилятором.
4. www.speex.org - домашняя страница кодека с документацией.
Исходники были допилены для поддержки узкополосного(NarrowBand 8КГц) и широкополосного(WideBand 16KHz) режимов.
Оптимизированы по скорости загрузки буферов через DMA.
По Flash памяти декодер занимает около 30КБ, RAM - около 5КБ(надо настроить такую большую кучу т.к. идёт динамическое выделение памяти). Для работы судя по описаниям требует минимум 8МГц(низкая тактовая мной не проверялась).
Ограничения или недостатки:
-только декодер(для уменьшения размера кодер вырезан);
-в узкополосном режиме минимальная скорость потока 8 килобит(Quality=4);
-только постоянный битрейт(CBR);
-арифметика с фиксированной точкой. И как я понял процедура умножения сигналов вносит некоторую ошибку. Это проявляется в небольшом звоне голоса. В широкополосном режиме звон почти не заметен.В любом случае простой ФНЧ на выходе ЦАП поможет улучшить звук.
Применение.
Планируется использовать в моём синтезаторе.
Также может быть интересен в простых конструкциях вроде говорящих часов как одночиповое решение.
Исходники.
Проект под KEIL MDK470.
В файле 'main.h' выбрать частоту дискретизации(8/16K) и размер кодированного кадра ENCODED_FRAME_SIZE, соответсвующие
параметрам выбранного звука.
В файле 'main.c' функция play_message() воспроизводит звук.
В проект включены варианты одного сообщения с разным уровнем сжатия.
Звук снимается с выхода ЦАП PA4. Через кондёр можно подключить высокоомный динамик или наушники.
Есть идейка использовать оба выхода ЦАП в противофазном режиме для увеличения мощности, это чтобы отказаться от УНЧ.
Проект доступен по ссылке:
http://yadi.sk/d/Js5nb6jLAHd3x
Он относится к категории CELP и обеспечивает хороший коэффициент сжатия (скорость потока 1-2 килобайта в сек).
За основу были взяты материалы:
1.Статья с Easyelectronics
http://we.easyelectronics.ru/STM32/vosp ... speex.html
2.AN2812 Vocoder demonstration using a Speex audio codec
on STM32F101xx and STM32F103xx microcontrollers -- порт узкополосного варианта(8КГц) на STM32.
3.AN0055 - Application Note. Speex Codec. Порт кодека под контроллеры EFM32 от Energy micro. К сожалению исходники комплектуются только скомпилированной либой и толку от них ноль целых хрен десятых. Зато есть утилита speexenc, конвертирующая звуковые WAV-чики в h-файлы. Которые потом легко цепляются компилятором.
4. www.speex.org - домашняя страница кодека с документацией.
Исходники были допилены для поддержки узкополосного(NarrowBand 8КГц) и широкополосного(WideBand 16KHz) режимов.
Оптимизированы по скорости загрузки буферов через DMA.
По Flash памяти декодер занимает около 30КБ, RAM - около 5КБ(надо настроить такую большую кучу т.к. идёт динамическое выделение памяти). Для работы судя по описаниям требует минимум 8МГц(низкая тактовая мной не проверялась).
Ограничения или недостатки:
-только декодер(для уменьшения размера кодер вырезан);
-в узкополосном режиме минимальная скорость потока 8 килобит(Quality=4);
-только постоянный битрейт(CBR);
-арифметика с фиксированной точкой. И как я понял процедура умножения сигналов вносит некоторую ошибку. Это проявляется в небольшом звоне голоса. В широкополосном режиме звон почти не заметен.В любом случае простой ФНЧ на выходе ЦАП поможет улучшить звук.
Применение.
Планируется использовать в моём синтезаторе.
Также может быть интересен в простых конструкциях вроде говорящих часов как одночиповое решение.
Исходники.
Проект под KEIL MDK470.
В файле 'main.h' выбрать частоту дискретизации(8/16K) и размер кодированного кадра ENCODED_FRAME_SIZE, соответсвующие
параметрам выбранного звука.
В файле 'main.c' функция play_message() воспроизводит звук.
В проект включены варианты одного сообщения с разным уровнем сжатия.
Звук снимается с выхода ЦАП PA4. Через кондёр можно подключить высокоомный динамик или наушники.
Есть идейка использовать оба выхода ЦАП в противофазном режиме для увеличения мощности, это чтобы отказаться от УНЧ.
Проект доступен по ссылке:
http://yadi.sk/d/Js5nb6jLAHd3x
-
fedyasolder

- Поставщик валерьянки для Кота
- Сообщения: 2168
- Зарегистрирован: Ср май 01, 2013 13:53:56
- Откуда: с пальмы в Рио-Инженейро
Re: Синтез речи на STM32F100
Я бы сделал не так. Наговорил все необходимые фразы, а потом порезал по серединам гласных. Таким образом проблема переходов решается. Но задача у меня обратная, как заставить мелкосхему принимать мою команду (неделю бошку ломаю).
электропримат паяю даже лёжа...
-
oleg110592
- Друг Кота
- Сообщения: 3832
- Зарегистрирован: Сб сен 10, 2011 17:46:25
Re: Синтез речи на STM32F100
старенькая тема. Так не пойдет?как заставить мелкосхему принимать мою команду
https://geektimes.ru/post/257382/
-
fedyasolder
- Поставщик валерьянки для Кота
- Сообщения: 2168
- Зарегистрирован: Ср май 01, 2013 13:53:56
- Откуда: с пальмы в Рио-Инженейро
Re: Синтез речи на STM32F100
Это для централизованного распознавания, дорого. Хочу на ATmega8 
электропримат паяю даже лёжа...
-
uk8amk
- Поставщик валерьянки для Кота
- Сообщения: 2222
- Зарегистрирован: Вт ноя 27, 2007 11:32:06
- Откуда: Tashkent
Re: Синтез речи на STM32F100
Для покрытия большей части русского словаря необходимо 4300 сегментов. Это по моим подсчётам дифонов.
Если резать только по гласным, то кол-во возрастает минимум в несколько раз.
В этом плане параметрический синтез с управляемыми генераторами требует намного меньше памяти, но больше математики.
Для распознавания команд есть простое и не очень хорошее решение для атмеги
http://www.polesite.ru/?p=2001
Если резать только по гласным, то кол-во возрастает минимум в несколько раз.
В этом плане параметрический синтез с управляемыми генераторами требует намного меньше памяти, но больше математики.
Для распознавания команд есть простое и не очень хорошее решение для атмеги
http://www.polesite.ru/?p=2001
-
fedyasolder
- Поставщик валерьянки для Кота
- Сообщения: 2168
- Зарегистрирован: Ср май 01, 2013 13:53:56
- Откуда: с пальмы в Рио-Инженейро
Re: Синтез речи на STM32F100
Не обязательно весь словарь иметь для частного случая. Параметрическое тоже хорошо, видел примеры.
электропримат паяю даже лёжа...